Audite Vocem
Startseite
Stimmkomponenten
Sprecherbeispiele
Glossar
Glossar
Adduktionsstärke
Laver beschreibt die laryngalen Spannungsverhältnisse bei der Produktion
der unterschiedlichen Phonationstypen anhand dreier Parameter: (1)
longitudinale Spannung (longitudinal tension), (2)
mediale Kompression (medial compression) und (3) Adduktionsstärke (adductive tension).
Die Adduktionsstärke gibt an, wie stark die Aryknorpel (Stellknorpel) an
ihrer hinteren Seite gegeneinander gezogen werden. Erreicht wird dies v. a. durch die
interarytenoideus-Muskeln (m. arytaenoideus obliquus und m. arytaenoideus
transversus), und darüber hinaus durch den m. cricoarytaenoideus lateralis.

Amplitude
Die Amplitude ist eine physikalische Größe, die die maximale Auslenkung
der Luftdruckschwankungen bei der Schallübertragung widerspiegelt. Sie wird
in decibel (dB) angegeben. Auditives Korrelat der Amplitude ist die Lautstärke.
Diplophonie
Zwei unterschiedlich schwingende Abschnitte der Stimmlippen schwingen mit unterschiedlichen Geschwindigkeiten, einer mit höherer Grundfrequenz und einer mit tieferer Grundfrequenz. Die zwei Grundfrequenzen sind auditiv wahrnehmbar. Diplophonie ist eine mögliche physiologische Basis für Knarren/Knarrstimme.

Eckfrequenz
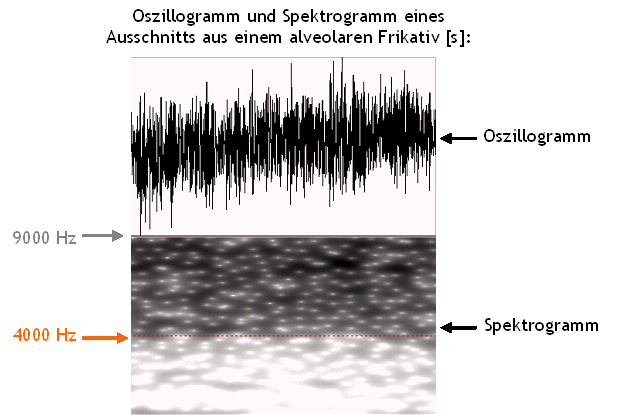
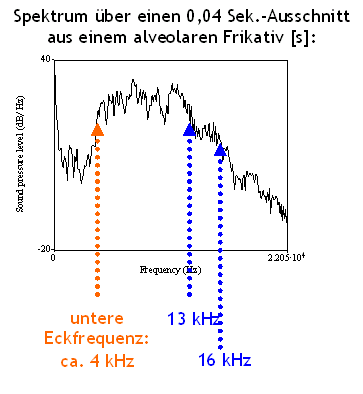
Die spektrale Struktur von Frikativen wird anhand ihrer sog. Eckfrequenzen (engl. cut-off frequency)
beschrieben: Bei vielen Frikativen nimmt die Energie im unteren Bereich ab einer
bestimmten Frequenz stark zu und im oberen Bereich ab einer bestimmten Frequenz
wieder schnell ab.
Die untere Eckfrequenz von palatalen Frikativen liegt z.B. zwischen 2 und 3 kHz,
von alveolaren Frikativen zwischen 4 und 5 kHz. Labiodentale Frikative haben
im Gegensatz dazu eine relativ gleichmäßige Energieverteilung über
alle Frequenzen, so dass bei ihnen keine Eckfrequenzen bestimmt werden können.
Elektroglottograph (Laryngograph)
Mit Hilfe eines Elektroglottographen (EGG), auch Laryngograph genannt, wird der
relative Kontakt der Stimmlippen gemessen.
Es handelt sich dabei um eine nicht-invasive Methode: Am Hals werden rechts und
links vom Kehlkopf - an den Seiten des
Schildknorpels - jeweils eine (zunehmend
häufiger zwei) Elektroden angelegt. Eine dient als Sender-, die andere als
Empfänger-Elektrode. Von der Sender-Elektrode wird ein hochfrequenter
Wechselstrom mit geringer Voltzahl ausgegeben. An der Empfänger-Elektrode
wird gemessen, wie viel von dem gesendeten Strom ankommt. Die EGG-Signale geben
also die Impedanz des Stromflusses an der
Glottis wieder: Luft bietet mehr Impedanz
als das Gewebe, weshalb bei hohem Kontakt der
Stimmlippen (= bei geschlossener
Glottis) geringere Impedanz vorliegt und somit mehr bei der Empfänger-Elektrode
ankommt.
Das Signal wird jedoch nicht nur von der Stärke des Stimmlippenkontakts
bestimmt. Variable Faktoren wie die vertikale Kehlkopfbewegung oder Schleim auf
den Stimmlippen können das Signal beeinflussen. Darüber hinaus bestimmen
feste Faktoren wie z.B. die Struktur des Fettgewebes, der Abstand der Elektroden
voneinander und der Kontakt zwischen Elektroden und Haut die Qualität des
Signals.
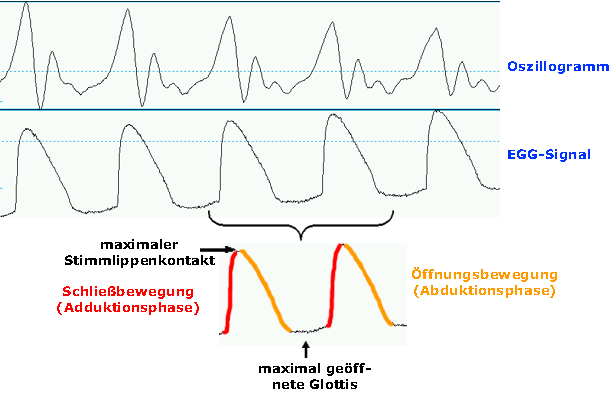
Wie liest man ein EGG-Signal?
Wie bei dem Oszillogramm des akustischen Signals wird auch das elektroglottographische
Signal in Wellenform dargestellt. Der maximale Stimmlippenkontakt (= minimale
Impedanz) bildet dabei den Gipfel der Welle, der Moment der am weitesten
geöffneten Glottis (= maximale Impedanz) liegt im unteren Signalbereich.
Die Phase der Stimmlippenadduktion bildet die linke Flanke der Welle, die Phase
der Abduktion die rechte. (Siehe Abb. unten)
Bei der Modalstimme dauert die Adduktionsphase normalerweise 1/3 der Periodendauer,
die Abduktionsphase 2/3 der Periodendauer (siehe Abb.). Bei behauchter Stimme
oder Falsett ist die Wellenform eher symmetrisch; bei Knarren hingegen wird die
Glottis sehr abrupt geschlossen, die Öffnung verläuft sehr langsam.
Falsche Stimmlippen
Die falschen Stimmlippen, auch Taschenfalten oder Ventrikularfalten genannt, sind
zwei Schleimhautfalten oberhalb des Kehlkopfes.
Sie werden bei einigen Stimmkomponenten wie z.B. starkem Knarren,
rauer oder gespannter Stimme durch starke pharyngale Kontraktionen adduziert und
nähern sich dabei den echten Stimmlippen an.
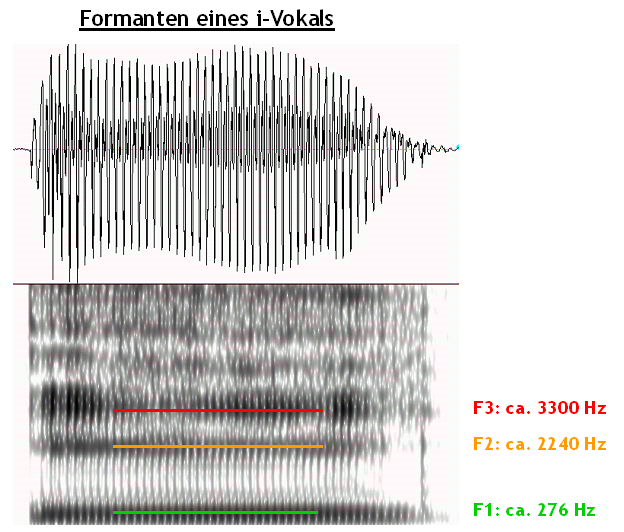
Formant
Aufgrund unterschiedlicher Konfiguration des Vokaltraktes bei unterschiedlichen
Lauten oder artikulatorischen Stimmkomponenten wird das Rohschallsignal in jeweils
spezifischer Weise gefiltert: Es werden bestimmte Frequenzbereiche verstärkt,
andere gedämpft. In der Akustik werden die Frequenzbereiche erhöhter
Intensität Formanten genannt, in Hertz (Hz) angegeben.
Formanten findet man v.a. bei stimmhaften Lauten, z.B. bei Vokalen. Da es
mehrere Intensitätsmaxima gibt, werden sie von dem niedrigsten Frequenzwert
zum höchsten durchnummeriert (der erste Formant hat den niedrigsten Wert).
Ein Beispiel: Der Vokal [i] hat einen niedrigen ersten Formanten und hohe Werte
für den zweiten und dritten Formanten. Bei einem männlichen Sprecher
sind folgende Werte zu erwarten: F1 von 250-300 Hz, F2 von 2200-2400 Hz, F3 von
ca. 2500 Hz. Der Vokal [a] hat im Vergleich dazu einen hohen ersten Formanten
und mittleren zweiten und dritten Formanten: F1 von ca. 600-650 Hz, F2 von
1300-1400 Hz, F3 von ca. 2300-2400 Hz.
Glottis
Als Glottis wird der Raum zwischen den
Stimmlippen
bezeichnet. Er wird auch
Stimmritze genannt. Bei einem harten Stimmeinsatz von Vokalen (dem
Glottalverschluss) ist die Glottis z.B. geschlossen. Beim Einatmen ist die Glottis
maximal weit geöffnet. Gelegentlich werden unter diesen Begriff die Stimmritze
und die sie eingrenzenden Stimmlippen zusammengefasst (in dieser Lernumgebung
aber nicht).
GRBAS-Skala
Skala zur Klassifikation pathologischer Stimmen mit Hilfe der Parameter Heiserkeit
(G), Rauhigkeit (R), Behauchtheit (B), Asthenie (A) und Spannung (S). Sie wird
vor allem im anglo-amerikanischen Raum verwendet.
In der Praxis korrelierte die Einschätzung von Asthenie jedoch so stark mit
Behauchtheit, dass sie als eigene Kategorie aufgegeben wurde. Ebenso streute die
Beurteilung der Spannung in den Hörerurteilen sehr stark. Dies führte
im deutschsprachigen Raum zur Einführung der
RBH-Skala, anhand
derer eine Stimmen über Rauheit (R), Behauchtheit (B) und Heiserkeit (H)
bestimmt wird.
Grundfrequenz (F0)
Häufigkeit, mit der sich die Stimmlippenschwingungen innerhalb einer Sekunde
wiederholen. Die Grundfrequenz wird in Hertz (Hz) angegeben. Sie liegt bei Männern bei ca. 100-150 Hz, bei Frauen bei ca. 190-250 Hz, bei Kindern bei ca. 350-500 Hz. Für diese Unterschiede sind v.a. unterschiedlich lange und dicke Stimmlippen bei Männern, Frauen und Kindern verantwortlich.
Auditives Korrelat: Tonhöhe.
Im Spektrogramm ist die Grundfrequenz als sog. voice bar (Stimmbalken) erkennbar: ein dicker schwarzer Balken im untersten Bereich des Signals.
Harmonische
Das akustische Sprachsignal ist keine Sinusschwingung, sondern besteht aus
mehreren Teilkomponenten. Die einzelnen Teilkomponenten werden Harmonische
genannt.
Bei (quasi-)periodischen Schwingungen ist die erste Harmonische (mit der
längsten Periodendauer) die
Grundfrequenz.
Alle weiteren Harmonischen, die ein Vielfaches der Grundfrequenz sind, werden
auch Obertöne genannt.
Die Harmonischen dürfen nicht mit
Formanten
verwechselt werden. Formanten sind Frequenzbänder, in denen die vorhandenen
Harmonischen verstärkt werden.
Kehlkopf (Larynx)
Der Kehlkopf stellt den Anfangsteil des unteren Atemwegs dar. Er dient primär dazu, das Eindringen von Speisen in die Luftröhre zu verhindern.
Er besitzt ein knorpeliges Kehlkopfskelett, dessen Einzelteile miteinander
in Gelenken artikulieren und durch diverse Bänder miteinander verbunden sind.
Der Kehlkopf wird zur Stimmbildung genutzt. Dazu befinden sich im Kehlkopfinneren
die beiden Stimmlippen. Je nachdem, ob die Stimmlippen
schwingen, die Glottis vollständig verschließen oder ob sie weit abduziert sind,
können unterschiedliche Lautklassen und unterschiedliche
Phonationstypen
produziert
werden.
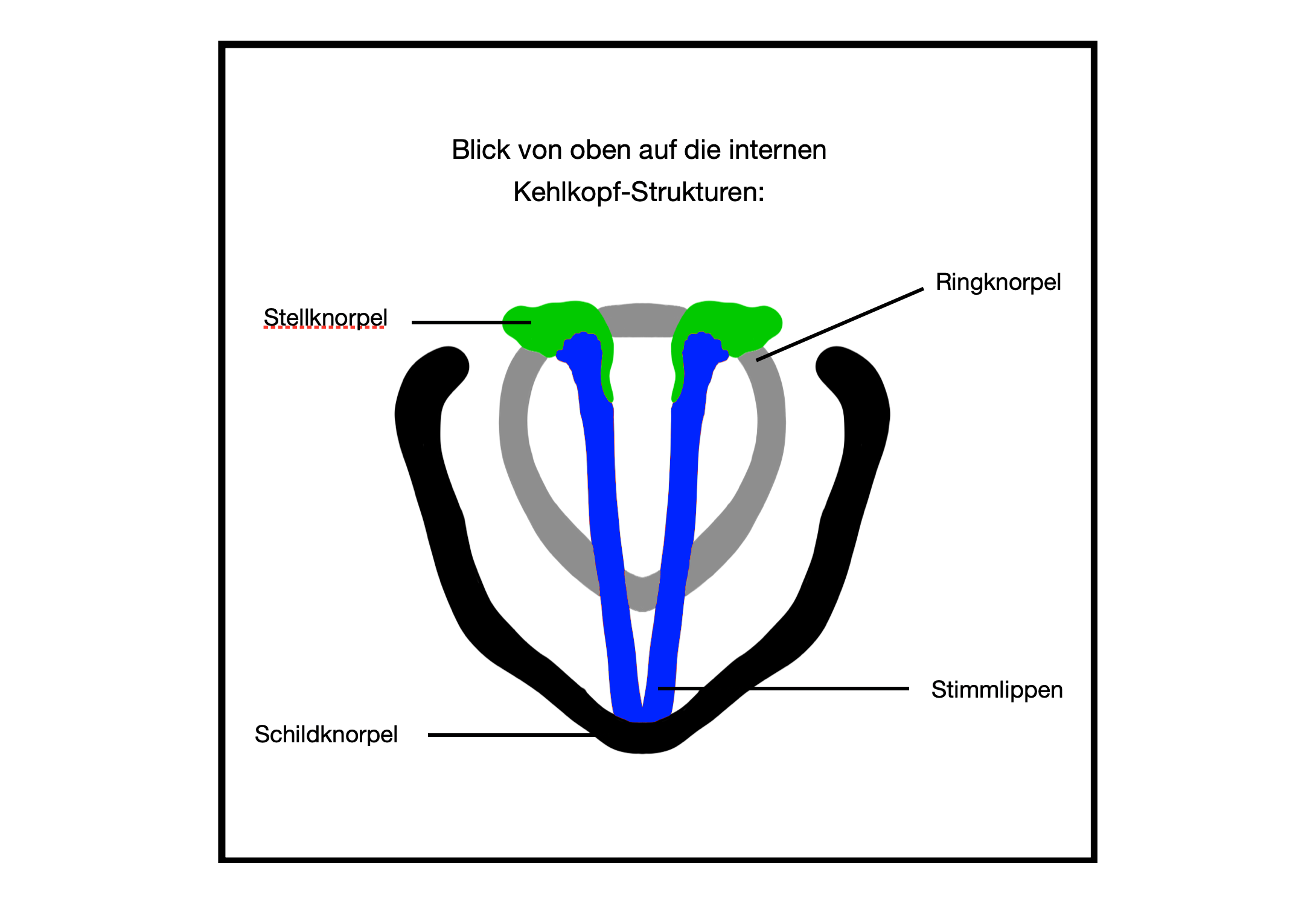
Die Knorpel des Kehlkopfs und die Befestigungspunkte der Stimmlippen sind hier abgebildet:

Grau eingezeichnet ist der sog. Ringknorpel (Cartilago cricoidea).
Die grün dargestellten Stellknorpel/Aryknorpel (Cartilagines arytenoidea) sind pyramidal geformt. Sie sitzen locker auf dem Ringknorpel auf und können relativ zu diesem nach vorne/hinten verschoben bzw. gedreht werden.
Die Stimmlippen sind hinten an den Processus vocales der beiden Stellknorpel und vorne an der Innenseite des Schildknorpelbugs angeheftet. Der schwarz eingezeichnete Schildknorpel (Cartilago thyroidea) dient u.a. dem Schutz der Stimmlippen. Die beiden Platten des Schildknorpels stehen bei Männern und Frauen sowie bei Kindern in unterschiedlichem Winkel zueinander. Beim Mann findet man einen Winkel von etwa 90 Grad, bei der Frau einen Winkel von etwa 120 Grad. Die vordere Spitze des Schildknorpels wird als Adamsapfel bezeichnet. Der Adamsapfel ist folglich beim Mann prominenter ausgebildet.
Langzeitspektrum
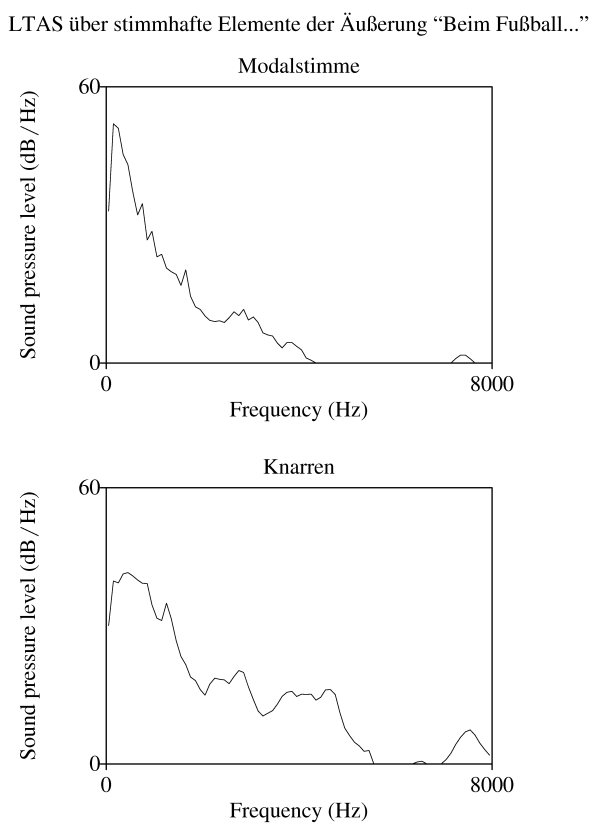
Langzeitspektren (engl. long term average spectra - LTAS) stellen die spektralen Eigenschaften eines Sprachsignals über einen größeren zeitlichen Ausschnitt dar. Dabei werden über einen Zeitraum von mindestens 40-60 Sekunden einzelne Spektren (mit Hilfe einer Fast Fourier Transformation - FFT) hintereinander erstellt und die Werte gemittelt. Um segmentelle Einflüsse auf die spektralen Werte ausschließen zu können, darf der Ausschnitt auf keinen Fall kleiner sein. Da aber auch dann der Effekt einzelner Laute nie ganz verschwindet, raten einige Autoren dazu, z.B. nur Vokale zu analysieren, oder nur stimmhafte Segmente. Außerdem ist es sinnvoll, Pausen herauszulöschen, da das Hintergrundrauschen das Signal unnötig verzerren könnte.
Mit Hilfe von Langzeitspektren kann man ein Profil von Gipfeln und Tälern erstellen und den spektralen Abfall bestimmen (indem man z.B. die Amplitude der ersten Harmonischen mit der Amplitude höherer Harmonischer vergleicht). Sie können so zur Charakterisierung einer Stimme (z.B. in der Sprechererkennung), als Maß für Geschlechts- oder Altersidentität und als Indiz für bestimmte Stimmpathologien dienen.
Die Einflüsse supralaryngaler Stimmkomponenten auf das Langzeitspektrum sind eher gering, so dass es primär für laryngale/phonatorische Stimmkomponenten ein valides Maß darstellt. Darüber hinaus haben viele Faktoren, die nichts mit der Stimmqualität zu tun haben (wie z.B. auch die Tagesform des Sprechers), einen Einfluss auf das Langzeitspektrum; die Vergleichbarkeit der einzelnen Spektren ist deshalb problematisch.
Beispiel für Langzeitspektren der zwei Stimmkomponenten Modalstimme und Knarren über alle stimmhaften Segmente des Beispielsatzes "Beim Fußball können die Sportfreunde immer davon ausgehen, dass die schönsten Tore und die interessantesten Spielzüge abends um zehn Uhr dreißig in der Sportschau übertragen werden." (mit Hilfe von praat erstellt):
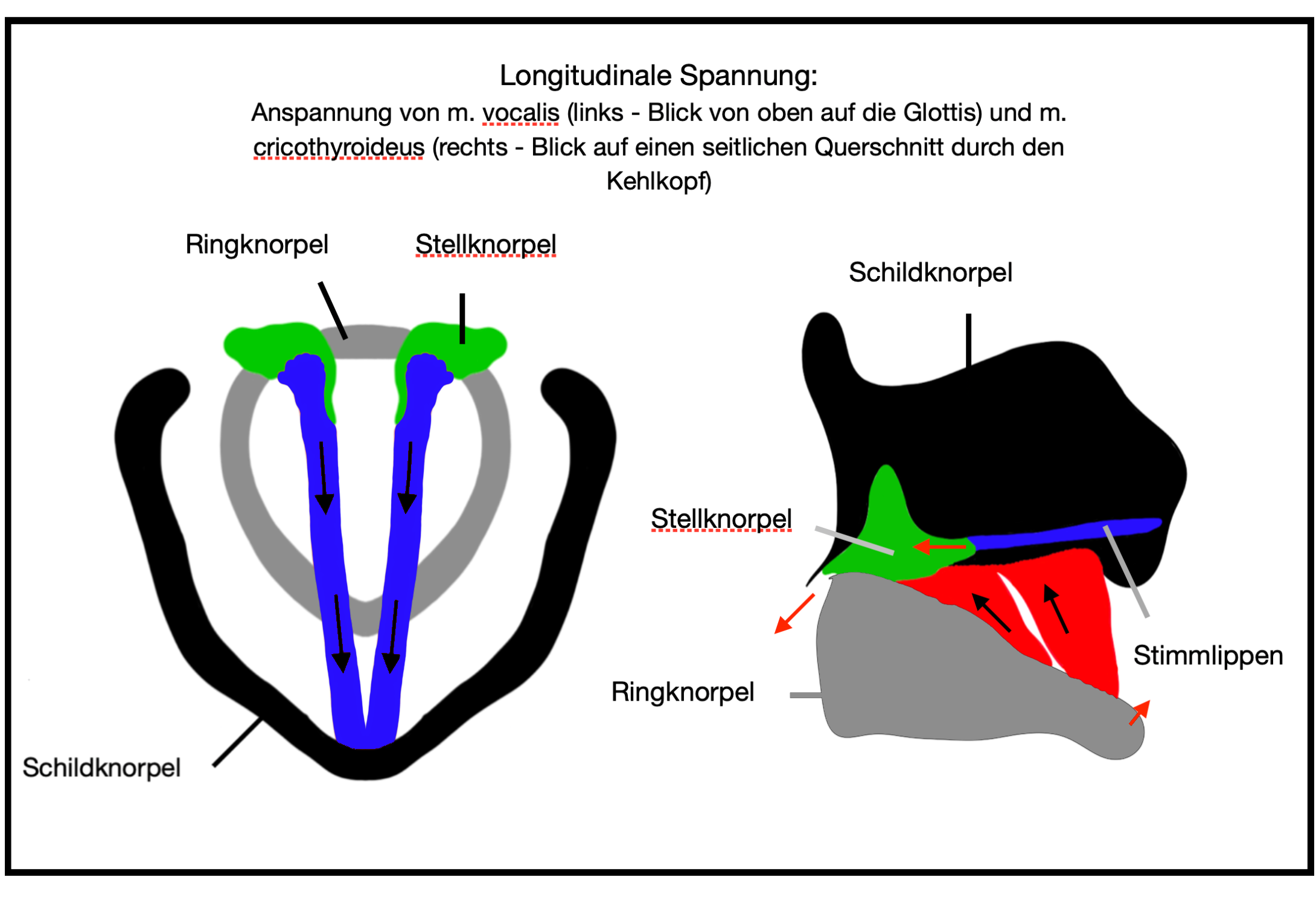
Longitudinale Spannung
Laver beschreibt die laryngalen Spannungsverhältnisse bei der Produktion
der unterschiedlichen
Phonationstypen
anhand dreier
Parameter: (1) Longitudinale Spannung (longitudinal tension), (2)
mediale Kompression (medial compression) und (3)
Adduktionsstärke (adductive tension).
Unter longitudinaler Spannung wird die - aktive und passive - Längsspannung
der Stimmlippen verstanden. Die passive Spannung wird durch das Nach-Vorne-Kippen
des Schildknorpels mit Hilfe des m. cricothyroideus und die damit einhergehende Dehnung der Stimmlippen erreicht, die aktive durch die Anspannung des vocalis-Muskels, der ein Teil der Stimmlippen selbst ist.
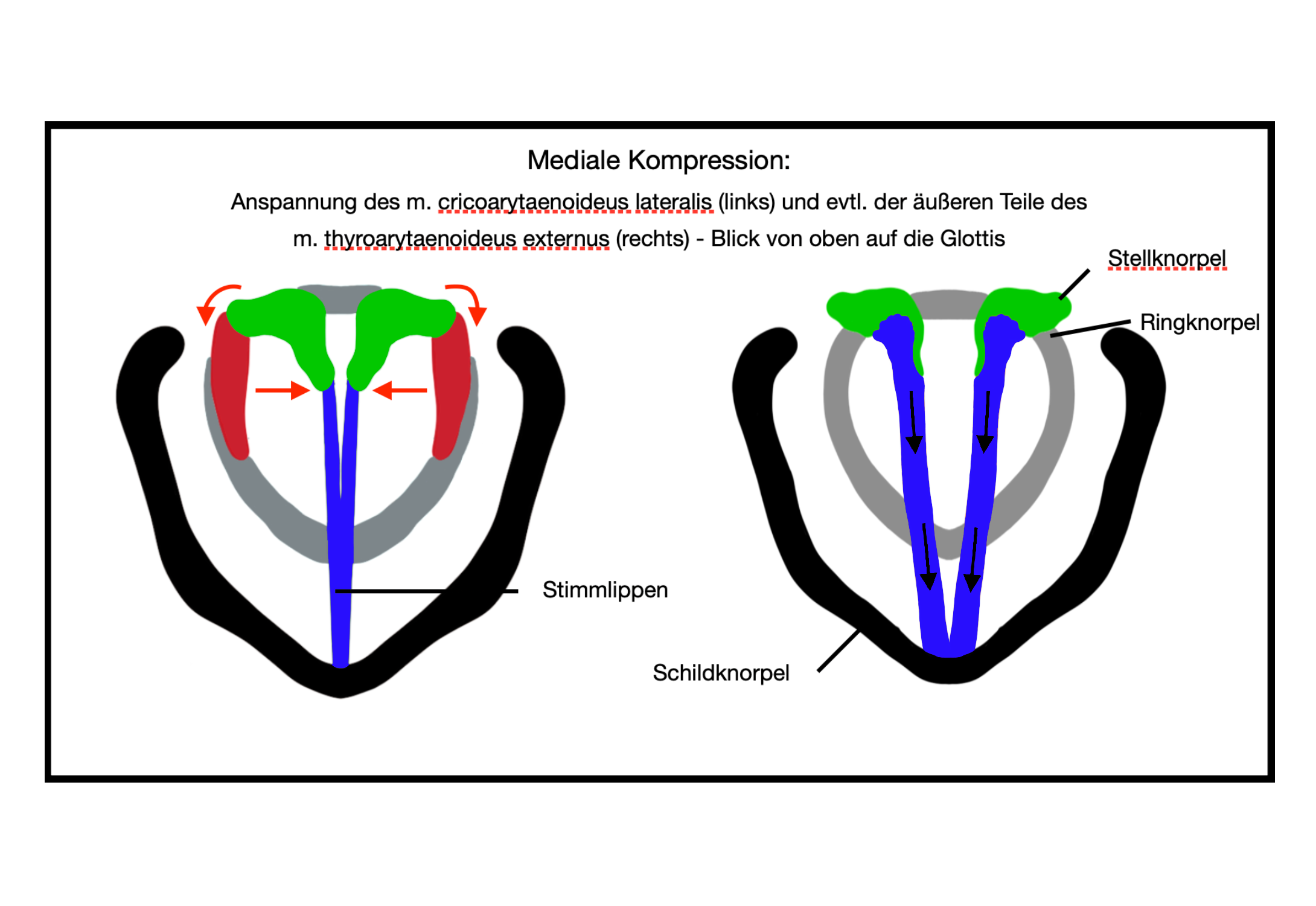
Mediale Kompression
Laver beschreibt die laryngalen Spannungsverhältnisse bei der Produktion
der unterschiedlichen
Phonationsstypen
anhand dreier
Parameter: (1) longitudinale Spannung (longitudinal tension),
(2) mediale Kompression (medial compression) und (3)
Adduktionsstärke (adductive tension).
Die mediale Kompression bestimmt die Stärke, mit der die vorderen Prozessus
der Aryknorpel (Stellknorpel) zusammengedrückt werden. Der m.
cricoarytaenoideus lateralis und Teile des m. thyroarytaenoideus externus
bewirken die notwendige Drehung der Aryknorpel.
Neutrale Stimmgebung, neutrale Artikulationsstellung
Referenzbasis für alle anderen Stimmkomponenten:
- Die Stimmlippen schwingen periodisch, mit moderater
Spannung. Die Schwingungen gehen nicht mit hörbarer Friktion einher.
- Der Kehlkopf ist weder abgesenkt noch erhöht.
- Die Spannung im Mund-, Rachen- und Kehlkopfraum ist gemäßigt.
- Der supralaryngale Vokaltrakt ist überall etwa gleich weit. Es kommt
zu keiner pharyngalen Verengung.
- Die Lippen sind nicht vorgestülpt.
- Das Zungenblatt wird in seinen vorderen Segmenten verwendet, die
Zungenwurzel ist nicht vorgeschoben und nicht zurückgezogen.
- Der Kiefer ist weder ganz geschlossen, noch besonders offen.
- Hörbare Nasalität liegt nur dort vor, wo linguistisch gewünscht.
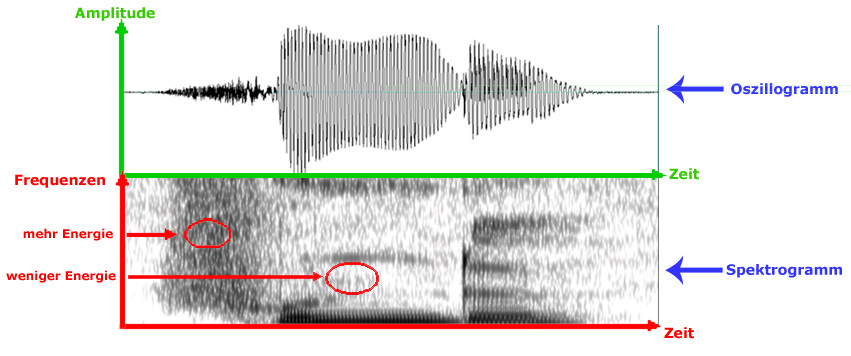
Oszillogramm und Spektrogramm
Ein Oszillogramm (auch Zeitsignal genannt) ist die Darstellung des Schalldrucksignals als komplexe Welle. Es werden folgende
akustische Parameter dargestellt:
- x-Achse: Zeit (ms) - vgl. Dauer in der Perzeption
- y-Achse: Amplitude (dB) - vgl. Lautstärke in der Perzeption
Das Spektrogramm stellt hingegen folgende Eigenschaften des akustischen Signals dar:
- x-Achse: Zeit (ms) - vgl. Dauer in der Perzeption
- y-Achse: Frequenz (Hz) - vgl. Tonhöhe in der Perzeption
- Schwärzungsgrad: Energie - vgl. Lautstärke in der Perzeption
Period doubling
Die Stimmlippen schwingen nicht regelmäßig:
Es wechseln sich Perioden unterschiedlicher
Amplitude
oder Periodendauer ab.
Period doubling ist eine mögliche physiologische Basis für
Knarren/Knarrstimme.
Phonation
Stimmbildung: Anregung des Sprachschalls durch Schwingen der
Stimmlippen.
Die Stimmkomponenten, die durch unterschiedliche Schwingungsverhältnisse
der Stimmlippen produziert werden, werden auch als Phonationstypen bezeichnet.
Phonationstyp
Die Anregung des Sprachschalls kann aufgrund unterschiedlicher Form der
Stimmlippenschwingungen differieren. Diese unterschiedlichen Phonationsarten
werden auch Phonationstypen genannt.
Die Stimmlippen können z.B. regelmäßig und effizient, ohne dass
Luft unmoduliert entweicht, schwingen; in diesem Fall spricht man von einer
Modalstimme. Wenn sie fest zusammengepresst werden und somit längere Zeit
adduziert sind und nur unregelmäßig schwingen können, spricht
man von einer Knarrstimme oder Knarren. Modalstimme und Knarren
sind zwei mögliche Phonationstypen.
RBH-Skala
Skala zur Beurteilung pathologischer Stimmen. Es wird angegeben, wie heiser, rau
oder behaucht eine Stimme ist.
Der Eindruck der Heiserkeit (H) ergibt sich aus dem der Rauheit (R) und dem der Behauchtheit
(B) der Stimme. Die RBH-Skala wird in unterschiedlichen Stärkegraden angegeben (nicht vorhanden,
leicht-, mittel- und hochgradig).
Rauheit wird primär durch irreguläre Grundfrequenzschwankungen bestimmt.
Behauchtheit wird durch unmoduliertes Turbulenzgeräusch bestimmt.
Spektraler Abfall
Ein Spektrum zeigt die Zusammensetzung eines akustischen Signals aus bestimmten
Frequenzen und deren Amplituden
zu einem bestimmten Zeitpunkt. In einem
Langzeitspektrum werden die gemittelten Frequenz-Amplitudenwerte über einen
bestimmten Zeitraum dargestellt.
Der spektrale Abfall (engl. spectral tilt) gibt an, in welchem Maße
die Amplitude höherer Frequenzen im Verhältnis zu den tieferen abnimmt.
Er wird bestimmt, indem z.B. die Amplitude der zweiten
Harmonischen oder des ersten
Formanten
ins Verhältnis zur Amplitude der ersten Harmonischen (der Grundfrequenz)
gesetzt wird.
Spektrum
Ein Spektrum zeigt die Zusammensetzung eines akustischen Signals aus bestimmten Frequenzkomponenten und deren Amplituden zu einem bestimmten Zeitpunkt. Bzw. in einem Langzeitspektrum werden die gemittelten Frequenz-Amplitudenwerte über einen bestimmten Zeitraum dargestellt.
In dem Spektrum eines (quasi-)periodischen Sprachsignals ist die erste Harmonische, die normalerweise eine hohe Intensität aufweist, die Grundfrequenz. Die Formanten sind als Intensitätsgipfel in den höheren Frequenzen zu erkennen.

Stimme
Mit diesem Begriff wird vor allem der am
Kehlkopf erzeugte Primärklang bezeichnet, die sog. Quelle. Sekundäre Modifikation bzw. Filterung im Vokaltrakt
(Rachen-, Mund- und Nasenraum) erzeugt Resonanzen, die der Unterscheidung von
Lauten und supralaryngalen Stimmkomponenten dienen. Primärklang und
supralaryngale Stimmkomponenten zusammen machen eine wahrgenommene
Stimmqualität aus.
Stimmkomponente (Setting)
Alle hier aufgelisteten Stimmkomponenten (Stimmeigenschaften) werden in der Nomenklatur von John Laver (siehe z.B. Laver, 1980) als Settings bezeichnet. Eine konkrete
Stimmqualität kann sich aus einem komplexen Zusammenspiel mehrerer Settings/Stimmkomponenten ergeben.
Ein Setting beschreibt eine bestimmte Einstellung oder Konfiguration der an der
Artikulation beteiligten Strukturen, die über mehr als ein Segment hinweg
anhält. Nicht jedes Segment (Vokal oder Konsonant) ist gleichermaßen empfänglich für
ein Setting. So wird man z.B. bei stimmlosen Konsonanten keinen Einfluss der laryngalen
Settings feststellen, bei Vokalen hingegen sehr stark.
Einige Settings können miteinander kombiniert werden, andere nicht. Unter
dem Menüpunkt Sprecher-Beispiele sind einige Stimmen zu hören, die
mehrere Settings mehr oder weniger stark miteinander vereinen.
Stimmlippen
Die Stimmlippen (plicae vocales), auch Stimmfalten genannt, sind die Basis der Phonation. Sie verlaufen V-förmig von der Innenseite des Schildknorpels (cartilago thyroidea) zu den Stimmfortsätzen der Stellknorpel (cartilago arytaenoideus). Sie bestehen aus den Stimmbändern (ligamentum vocalis), Muskelgewebe (m. thyroarytaenoideus externus und m. vocalis) und Schleimhäuten.
Der Raum zwischen den Stimmlippen wird als Glottis oder Stimmritze bezeichnet.
Folgende Abbildung zeigt die Kehlkopf-internen Knorpelstrukturen und die Stimmlippen:
Stimmqualität
Eine Qualität, die quasi-permanent bzw. über mehr als ein Segment
hinweg von einem neutralen Artikulationsmodus abweicht. Eine konkrete Stimmqualität kann sich aus einem komplexen Zusammenspiel mehrerer Settings/Stimmkomponenten ergeben.
Hier wird eine breite Definition von Stimmqualität vertreten: Darunter fallen
nicht nur die am Kehlkopf modifizierten Phonationstypen
(= enge Definition von Stimmqualität), sondern auch alle Veränderungen, die im supralaryngalen
Vokaltrakt vorgenommen werden, und solche, die durch die allgemeine Spannung im
laryngalen und supralaryngalen Raum hervorgerufen werden.
Die Ursachen und Gründe für das Auftreten von Stimmqualitäten sind
vielfältig.
- Sie können extralinguistisch durch pathologische Veränderungen
von Stimmlippen oder Artikulatoren bestimmt sein.
- Linguistisch werden sie z.B. in Kombination mit bestimmten suprasegmentellen
Merkmalen wie Akzenttypen eingesetzt.
- Häufig dienen sie paralinguistischen Zwecken, z.B. der Signalisierung
von Emotionen und Einstellungen.
- Sie sind z.T. soziolinguistische Hinweise, z.B. auf die Zugehörigkeit
zu einer bestimmten dialektalen Sprachgemeinschaft oder auch zu einer bestimmten
Altersgruppe.
supralayngal
Unter die supralaryngalen Stimmkomponenten fallen die Abweichungen von der neutralen Artikulationsstellung, die den Bereich oberhalb des Kehlkopfs betreffen.
- Abweichungen von der neutralen (horizontalen) Zungenposition im Mundraum
- Abweichungen von der neutralen Lippenform
- Abweichungen in der vertikalen Kieferposition (dem Öffnungsgrad des Mundes)
- Nasalierung und Denasalierung
- Eine besondere Verengung oder Weitung des pharyngalen Raumes
Velopharyngale Pforte
Als velopharyngale Pforte wird der Durchgang zwischen Rachen- und Nasenraum
bezeichnet. Das Velum (velum palatinum, auch Gaumensegel genannt), der
weiche Teil des Gaumens, kann durch diverse Muskeln angehoben und abgesenkt werden.
Ist das Velum angehoben, ist die velopharyngale Pforte geschlossen und es kann
keine Luft in die Nase fließen. Bei gesenktem Velum ist die velopharyngale
Pforte geöffnet, so dass Luft in die Nase fließen kann; es werden
nasale Laute produziert bzw. der Sprecher spricht mit Nasalierung.
Velopharyngale Stimmkomponenten
Dieser Begriff wird einer Kategorie velar bedingte Stimmkomponenten
vorgezogen, weil nicht nur das Velum an der Verengung oder Öffnung der sog.
velopharyngalen Pforte - dem Durchgang zwischen Rachen- und Nasenraum - beteiligt ist.
Ein weiteres Problem liegt in der artikulatorischen Basis für einen nasalen
auditiven Eindruck: Was man wahrnimmt, ist vielmehr eine Seitenkammern-Resonanz.
Seitenkammer ist in den hier präsentierten Beispielen die Nase, könnte
aber z.B. auch der Rachenraum sein; der akustische und auditive Effekt wäre
sehr ähnlich oder gar gleich.
Vokaltrakt
Der Vokaltrakt, gelegentlich als Ansatzrohr bezeichnet, ist der Artikulationsraum oberhalb des Kehlkopfs. Darunter fallen Rachen-, Nasen- und Mundraum.
Das (durch Phonation angeregte) Quellsignal wird hier gefiltert: Einige Frequenzbereiche des Rohschallsignals haben viel Energie. Man spricht dabei von Resonanzfrequenzen. Andere Frequenzbereiche werden durch Absorption der Energie am Gewebe oder durch Verlust in den subglottalen Raum stark gedämpft.