7.1.3 Combining Top-down and Bottom-up Information
Combine top-down processing with bottom-up processing in order to avoid going wrong in the ways that we are prone to go wrong with pure top-down and pure bottom-up techniques.
As the previous two examples have shown, using a pure top-down approach, we are missing some important information provided by the words of the input string which would help us to guid our decisions. However, similarly, using a pure bottom-up approach, we can sometimes end up in dead ends that could have been avoided had we used some bits of top-down information about the category that we are trying to build.
The key idea of left-corner parsing is to combine top-down processing with bottom-up processing in order to avoid going wrong in the ways that we are prone to go wrong with pure top-down and pure bottom-up techniques. Before we look at how this is done, you have to know what is the left corner of a rule.
The Left Corner
The left corner of a rule is the first symbol on the right hand side. For example, 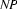 is the left corner of the rule
is the left corner of the rule 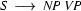 , and
, and 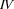 is the left corner of the rule
is the left corner of the rule 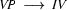 . Similarly, we can say that
. Similarly, we can say that 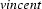 is the left corner of the lexical rule
is the left corner of the lexical rule 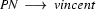 .
.
A left-corner parser alternates steps of bottom-up processing with top-down predictions. The bottom-up processing steps work as follows. Assuming that the parser has just recognized a noun phrase, it will in the next step look for a rule that has an as its left corner. Let's say it finds 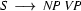 . To be able to use this rule, it has to recognize a
. To be able to use this rule, it has to recognize a 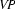 as the next thing in the input string. This imposes the top-down constraint that what follows in the input string has to be a verb phrase. The left-corner parser will continue alternating bottom-up steps as described above and top-down steps until it has managed to recognize this verb phrase, thereby completing the sentence.
as the next thing in the input string. This imposes the top-down constraint that what follows in the input string has to be a verb phrase. The left-corner parser will continue alternating bottom-up steps as described above and top-down steps until it has managed to recognize this verb phrase, thereby completing the sentence.
A left-corner parser starts with a top-down prediction fixing the category that is to be recognized, like for example 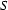 . Next, it takes a bottom-up step and then alternates bottom-up and top-down steps until it has reached an .
. Next, it takes a bottom-up step and then alternates bottom-up and top-down steps until it has reached an .
To illustrate how left-corner parsing works, let's go through an example. Assume that we again have the following grammar:
|
|
|
|
|
|
|
|
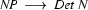
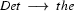
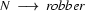
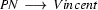
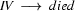
Now, let's look at how a left-corner recognizer would proceed to recognize vincent died.
1.) Input: vincent died. Recognize an . (Top-down prediction.)
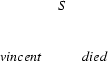
2.) The category of the first word of the input is 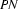 . (Bottom-up step using a lexical rule.)
. (Bottom-up step using a lexical rule.)
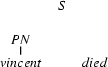
3.) Select a rule that has at its left corner: 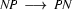 . (Bottom-up step using a phrase structure rule.)
. (Bottom-up step using a phrase structure rule.)

4.) Select a rule that has at its left corner: 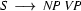 . (Bottom-up step.)
. (Bottom-up step.)
5.) Match! The left hand side of the rule matches with , the category we are trying to recognize.
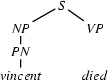
6.) Input: died. Recognize a . (Top-down prediction.)
7.) The category of the first word of the input is . (Bottom-up step.)
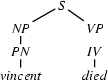
8.) Select a rule that has at its left corner: 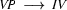 . (Bottom-up step.)
. (Bottom-up step.)
9.) Match! The left hand side of the rule matches with , the category we are trying to recognize.
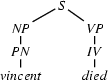
Make sure that you see how the steps of bottom-up rule application alternate with top-down predictions in this example. Also note that this is the example that we used earlier on for illustrating how top-down parsers can go wrong and that, in contrast to the top-down parser, the left-corner parser doesn't have to backtrack with this example.