7.1.2 Going Wrong with Bottom-up Parsing
Any possible "child" consituents are built, no matter whether they eventually fit into a suitable "mother" constituent.
As we have seen in the previous example, top-down parsing starts with some goal category that it wants to recognize and ignores what the input looks like. In bottom-up parsing, we essentially take the opposite approach: We start from the input string and try to combine words to constituents and constituents to bigger constituents using the grammar rules from right to left. In doing so, any possible "child" consituents that can be built are built; no matter whether they eventually fit into a suitable "mother" constituent (an 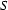 in the end).
in the end).
Ignoring the Overall Goal
No top-down information of the kind ``we are at the moment trying to built a sentence'' or ``we are at the moment trying to built a noun phrase'' is taken into account. Let's have a look at an example.
Say, we have the following grammar fragment:
|
|
|
|
|
|
|
|
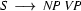
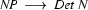
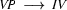
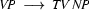
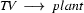
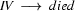
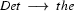
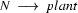
Note, how plant is ambiguous in this grammar: it can be used as a common noun or as a transitive verb. If we now try to bottom-up recognize ``the plant died'', we would first find that the is a determiner, so that we could rewrite our string to Det plant died. Then we would find that plant can be a transitive verb giving us Det TV died. Det and TV cannot be combined by any rule. So, died would be rewritten next, yielding Det TV IV and then Det TV VP. Here, it would finally become clear that we took a wrong decision somewhere: nothing can be done anymore and we have to backtrack. Doing so, we would find that plant can also be a noun, so that Det plant died could also be rewritten as Det N died, which will eventually lead us to success.