Design a simple ambiguous context free grammar. Show that your grammar is ambiguous by giving an example of a string that has two distinct parse trees. Draw the two trees.
The following grammar (epsilon.pl ) contains a rule producing an empty terminal symbol: S → ε
s ---> []. s ---> [left,s,right]. lex(a,left). lex(b,right).Does this grammar admit the string a b? What happens if you try to use bottomup_recognizer.pl with this grammar to recognize the string a b? Why?
Our naive bottom-up recognizer only recognizes strings of category s. Change it, so that it recognizes strings of any category, as long as the whole string is spanned by that category, and returns the category that it found. For example:
?- recognize_bottomup_any([the,man],Cat). Cat = np yes ?- recognize_bottomup_any([the,man,dances],Cat). Cat = s yes ?- recognize_bottomup_any([the,man,dances,a],Cat). no
Using the ourEng.pl grammar, give a detailed top-down depth-first analysis of Marsellus knew Vincent loved Mia. That is, start with:
 Figure 1: Starting State for Exercise. Ex. |
and then show all the steps of your work, including the backtracking.
Using the ourEng.pl grammar, give a detailed top-down breadth-first analysis of Marsellus knew Vincent loved Mia. That is, start with:
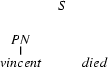 Figure 1: Starting Bag for Exercise. Ex. |
and then show all the steps of your work.
Can topdown_recognizer.pl or topdown_parser.pl handle the following grammar (leftrec.pl )?
s ---> [left,right]. left ---> [left,x]. left ---> [x]. right ---> [right,y]. right ---> [y]. lex(a,x). lex(b,y).If you are not sure try it. Why does it not work? How can it be fixed?
As we said in » Top Down Parsing in Prolog, we need a pretty printer that translates list representations of parses (like [s, [np, [pn, vincent]], [vp, [tv, shot], [np, [pn, marsellus]]]]) to trees. As an example, see a pretty printer for so called semantic tableaux that was written in Prolog. Just select some example from the boxes and then click on "send". Here, the output is a html-table. Write some pretty printer for the parses we have seen before (it might also produce latex or plain ascii or whatever format you like).