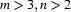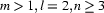1.8 Exercises and Solutions
Practise!
1.8.1 Exercises
Ex.
Exercise 1.1
Now, you are able to write your own automata. You can then use the
recognizeandgeneratepredicates to test them. So, here is a task which is a bit more interesting: Write an FSA (First, as a graph and, then, in Prolog notation!) that recognizes English noun phrases constructed from the following words: a, the, witch, wizard, Harry, Ron, Hermione, broomstick, brave, fast, with, rat. E.g.
the brave wizard
the fast broomstick
the wizard with the rat
Ron
...
Exercise 1.2
In the lecture, we represented
a1in Prolog as follows:start(a1,1).
final(a1,4).
trans(a1,1,2,h).
trans(a1,2,3,a).
trans(a1,3,4,!).
trans(a1,3,2,h).But we could also have represented it like this:
start(a1,1).
final(a1,4).
trans(a1,1,2,h).
trans(a1,2,3,a).
trans(a1,3,2,h).
trans(a1,3,4,!).Does it make any difference which way we represent it?
Exercise 1.3
Here's the code for
recognize1given in the lecture:recognize(A,Node,[]) :-
final(A,Node).
recognize(A,Node_1,String) :-
trans(A,Node_1,Node_2,Label),
traverse(Label,String,NewString),
recognize(A,Node_2,NewString).Suppose we changed it to this:
recognize(A,Node,[]) :-
final(A,Node),!.
recognize(A,Node_1,String) :-
trans(A,Node_1,Node_2,Label),
traverse(Label,String,NewString),!,
recognize(A,Node_2,NewString).What effect would this change have? What sort of
FSAs would not be affected by the change?
Exercise 1.4
Write
FSAs that generate the following languages (where e.g. bywe mean the result of repeating
m-times):
where
where