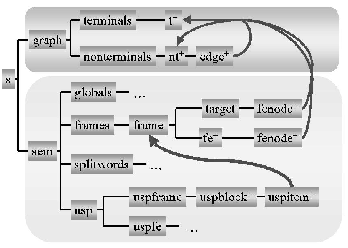
The tree in Figure 12 shows the implementation of this model in TIGER/SALSA. The nodes correspond to XML elements, and the edges to permissible embeddings. Elements that may be repeated are marked with a ``
A sentence (an <s> element) has two parts, one for the syntactic structure, (the <graph> element in the upper part) and one for the semantic roles (the <sem> element in the lower part). In TIGER XML without semantic annotation, a sentence has only one child, <graph>. It lists each terminal node as a <t> element below <terminals>, and each nonterminal node as a <nt> element below <nonterminals>. Edges are realised not via XML element embedding, but with explicit <edge> elements that refer to nodes via their unique identifiers, depicted as arrows in Fig. 12 . This allows for crossing edges and hence for a uniform treatment of continuous and discontinuous constituents.
TIGER/SALSA XML adds a layer of semantic information by introducing the additional semantics element <sem>, leaving the syntactic representation in <graph> unchanged. <sem> contains a straightforward representation of the semantic annotation for the current sentence, as modelled in Section 8.2. Again, all references to (either syntactic or semantic) entities are expressed in terms of identifiers to keep the levels of representation separate.
The <frames> element contains the role-semantic information proper. Similar to syntax, nodes and edges of frame trees are represented as explicit elements <frame>, <target> and <fe>. For all semantic nodes and edges, we introduce new globally unique IDs, such that semantic roles crossing sentence boundaries do not need special treatment, as reference to unique
The <globals> element contains tags such as 'is metaphoric' or '(needs) reexamination'. In the <splitwords> element, we record the treatment of German compound nouns, effectively introducing new terminal nodes ``below'' the original terminals. Underspecification is recorded in <usp>. One <uspblock> inside <uspframe> describes one case of frame underspecification, each <uspitem> child referring to one frame involved in the underspecification (by its unique ID). <uspfe> handles frame element underspecification in the same manner.
In TIGER/SALSA XML, the different annotation levels are kept in two separate blocks. The format is not standoff in the strictest sense, as all information about a sentence is collected within one <s> element. However, the annotation levels could in principle be decoupled completely because all reference between annotation levels is via identifiers that are unique throughout the corpus.