9.2.3 A Second Example
A second example.
The example before has shown that tableaux offer a data structure rich enough for maintaining different ways of understanding (parts of) a discourse. By organising tableaux expansion the way we do, in particular by concentrating on the expansion of one branch at a time, we can model the process of incrementally understanding a discourse. As we have seen in the example, this involves discarding one branch (i.e. partial model) and starting the model building process anew based on another branch if we encounter an inconsistency.
But using the ability to detect inconsistencies built into our model generation approach, we can do much more than we've seen so far. We can deal with lots of other kinds of ambiguities in the sentences we process. As our next case study, let's use inconsitency detection to resolve a syntactic ambiguity. The sentence in ( Sentence 1) has two syntactic readings (2) and (3)
Sentence 1:``Peter loves Mary and Mary sleeps or Peter snores.''
Reading 1:
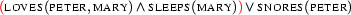
Reading 2:
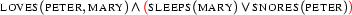
Of course normally such an ambiguity would be resolved in the syntax- or semantic construction-component, e.g. on the base of prosodic information. But for the sake of our example, let's assume our system isn't that clever. Thus at first, we will have to consider both of the above readings in parallel. We can do so by simply building two tableaux, one per reading.
Let us first look at Reading 2.

We see that model generation gives us two models. In both, Peter loves Mary. But in the first one, Mary sleeps, while in the second one Peter snores. If we take the logically different input (Reading 1), we obtain different models:

Let's continue the discourse with:
Sentence 2:``Peter does not love Mary.''
We have to extend the second tableaux to:
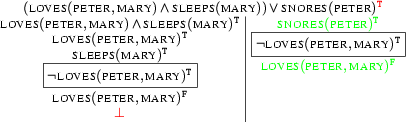
On this tableaux, we now have exactly one model. And the first tableaux closes altogether when extended with our second sentence.
?- Question
Check this claim!
This means that we've resolved all ambiguities. The choice of models has been reduced to one, which constitutes the intuitively correct reading of the discourse (Sentence 1 and Sentence 2).