9.1.1 Why Model Generation?
Motivation of model generation.
In the following we will use a model generation procedure to model discourse understanding. This approach takes us one step beyond what we've done so far. Take for example the sentence ``John loves Mary and Mary hates John''. Up to now we would have said that understanding this sentence (at least for a computer) consisted in constructing the formula 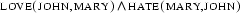 . From now on, we say that understanding the sentence also involves deriving the literals
. From now on, we say that understanding the sentence also involves deriving the literals 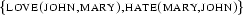 .
.
Why should we be so keen on deriving although we've already got their conjunction . What's so special about a set of implied literals compared to a complex formula that implies them? The answer is that they represent the truth conditional content of the sentence in its basic form. This makes them interesting in many respects:
- Formally,
a set of literals derived from a formula specifies a model for that formula (and that's why we call the process of deriving it model generation). We discussed the relation between sets of literals and models in Section 2.1.4. In our example, the literals
specify a model with a domain consisting of 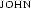 and
and 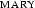 , where John loves Mary and Mary hates John. We shall even sloppily say that the literals are this model.
, where John loves Mary and Mary hates John. We shall even sloppily say that the literals are this model.- Technically,
a flat list of literals is a nicer and more easily accessible data structure than a formula with recursive structure. We can view model generation as a normalization-like postprocessing step after semantics construction. Additionally we already have a tool that works on input of that form: Our model checker from Chapter 2. We could give it the model
[love(john,mary), hate(mary,john)]and have it decide whetherforall(X, love(X,mary))is true in this model or not.- Conceptually,
the literals derived by a model generation procedure are more fundamental than the complex formula they are derived from. Ideally they stand for basic, logically independent facts that characterize a real-world situation where the complex formula would be true. By logically independent, we mean that the truth of each such basic fact depends only on the way the real world is, not on the truth of any other facts.
Complex sentences are in general not logically independent of one another. For example, the truth of the complex sentence ``John loves Mary and Mary hates John'' interferes with that of ``John loves Mary or Mary hates John''. In contrast the basic fact ``John loves Mary'' may or may not hold in a situation, independently from the equally basic ``Mary hates John'' (and independently from all other facts): There can be two situations that only differ in whether John loves Mary or not.
Of course it is a strong idealization to assume that all literals that we derive from the semantic representations we've discussed are really logically independent. For instance the two literals
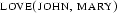 and
and 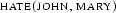 obviously should not be said to be independent - either John loves Mary or he hates her, but normally not both at the same time. The problem here is that our semantic treatment of single words is by far not fine-grained enough. We basically translate each verb or noun into one single predicate symbol of its own. But there exist various meaning relations between single words. The area of lexical semantic s takes such relations as one starting point for working out elaborate models of the internal structure of word meanings.
obviously should not be said to be independent - either John loves Mary or he hates her, but normally not both at the same time. The problem here is that our semantic treatment of single words is by far not fine-grained enough. We basically translate each verb or noun into one single predicate symbol of its own. But there exist various meaning relations between single words. The area of lexical semantic s takes such relations as one starting point for working out elaborate models of the internal structure of word meanings.- Cognitively,
a set of literals can serve as an approximation of what is called a mental model in the psychological literature. It is assumed that mental models are what constitutes believes and knowledge about the real world in human minds. Communication by natural language is then viewed as a process of transporting parts of the mental model of the speaker into the the mental model of the hearer. Therefore, the interpretation process on the part of the hearer is a process of integrating the meaning of the utterances of the speaker into his mental model.
We can take (sets of) literals as the currency for the information transferred in this process. What makes this choice of currency particularily interesting is that sets of literals are well-defined and have enough internal structure to allow us to formulate empirically testable hypotheses. For example they give us a means of claiming that we transfer more information by uttering ``John loves Mary and Mary hates John'' than by just saying ``Mary hates John''. In the first case the hearer potentially has to integrate two literals (i.e. two ``pieces of information'') into her mental model, compared to only one in the latter case. We could thus e.g. predict that understanding the first sentence would consume more resources than understanding the second one.