From Regular Expressions to FSAs
Abstract:
Proof, that there is a FSA for every regular expression.
We now prove one direction of the equivalence between regular expressions and FSAs: We will show that there is a FSA for every regular expression. The nice thing about this proof is that it is contructive - it proceeds by showing us what such an automaton will actually look like.
Our proof is by induction over the number of operators (that is, occurences of concatenation, ∣ and ∗) in a regular expression. We first show that there are automata for all possible singleton regular expressions. Then we assume that there are automata for the regular expressions with less than n operators, and show that there is one for each regular expression with n operators.
We first have to look at regular expressions without any operators. This means, we are talking about ∅, ɛ or a for some a∈Σ. For ∅ we can use the following automaton:
 Figure 4: finite-state for the Empty Language. finite-state for the empty language. |
Obviously, we can never get to the final state in this automaton, therefore no word is accepted.
For ɛ, the following automaton can be given:
 Figure 7: finite-state for the Language Containing only the Empty Word. finite-state for the Language Containing only the empty word. |
In this automaton we are at the final state at the moment we begin our computation (and we cannot get out of it). Therefore the automaton accepts only "input" having no symbol (that is: the empty word).
Now let's turn to complex regular expressions, i.e. ones that do contain operators. More precisely, we assume that there are automata for the regular expressions with fewer than i operators (with i≥1), and take a regular expression r with i operators. We have to look at three cases.
- Concatenation: r=r1r2
- Union: r=r1∣r2
- Kleene Closure: r=r1∗
In all three cases,
r1 and (where applicable)
r2 have
i−1 operators. Therefore there are FSAs for them by our induction hypothesis. We now have to build an automaton for
r on the basis of these given automata. All we have to do is make a few additions according to the additional operator used in
r. We will basically apply the ideas already seen in
» Examples of Regular Expressions.
Let's go through the cases one by one. We assume that M1 is an automaton for r1, M2 corresponds to r2, and that the states in M1 are disjoint from those in M2 (we can always achieve this by renaming):
1.
We construct an automaton M that consists of M1 and M2in series. That is, M will accept a word by running M1 on the first part, then jumping to M2 and running it on the second part of the word. M will look like this:
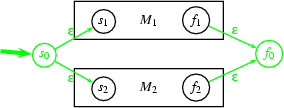 Figure 14: An Automaton that Consists of M1 and M2 in Series. An automaton that consists of and in series. |
The start state of M1 is also the start state of M, and the final state of M2 is also the final state of M. The final state of M1 and the start state of M2 have become "normal" states, but are now connected by a jump arc. Formally (where indices 1 and 2 indicate that an entity originally belongs to M1 or M2): M=(Q1∪Q2,Σ1∪Σ2,δ1∪δ2∪{((f1,ε),s2)},s1,{f2})
2.
We construct an automaton M that consists of M1 and M2in parallel. That is, M will accept a word by jumping into eitherM1orM2, running it on the word, and then jumping to a new final state. M will look like this:
 Figure 15: An Automaton that Consists of M1 and M2 in Parallel. An automaton that consists of M1 and M2 in parallel. |
The new start state s0 is connected by jump arcs to the former start states of M1 and M2. Thus it serves as the common start state for going through M1orM2. Similarly, the former final states of M1 and M2 are now both connected to a new final statef0 by jump arcs. This new final state serves as the common final state for going through M1orM2. Formally, the new automaton looks like this: M=(Q1∪Q2∪{s0,f0},Σ1∪Σ2,δ1∪δ2∪{((s0,ε),s1),((s0,ε),s2),((f1,ε),f0),((f2,ε),f0)},s0,{f0})
3.
We build a new automaton M that "embeds" M1. In M we can either bypass M1 and jump directly from the start state to the final state, or loop by jumping into M1, going through M1, and then jumping back to the (former) start state of M1. After looping an arbitrary number of times on M1, we can jump to the final state. Thus M accepts ε (via the bypassing jump arc) as well as all combinations of words that are accepted by M1 (by looping on the M1-part of M). Here's the picture:
 Figure 16: A New Automaton M that ``Embeds'' M1. A new automaton M that ``embeds'' M1. |
We had to add two states (the new start and final states s0 and f0), and four jump edges (one into M1, one out of M1, one to bypass it and one to loop). Thus this is the formal characterization of the new automaton M:
M=(Q1∪{s0,f0},Σ1,δ1∪{((s0,ε),s1),((f1,ε),f0),((s0,ε),f0),((f1,ε),s1)},s0,{f0})
So we've shown that for any regular expression there is an FSA that characterizes the same language. And in fact we've also shown how to construct such an automaton from any given regular expression. We just have to formulate a recursive procedure based on our inductive proof. We won't give an implementation that builds FSAs based on regular expressions here. But parts of the proof we've just seen will be very useful in
» Implementing Operations on FSAs, where we implement a tool for performing operations on given FSAs.