2.3.2 Morphological Parsing
The goal of morphological parsing is to find out what morphemes a given word is built from.
The goal of morphological parsing is to find out what morphemes a given word is built from. For example, a morphological parser should be able to tell us that the word cats is the plural form of the noun stem cat, and that the word mice is the plural form of the noun stem mouse. So, given the string cats as input, a morphological parser should produce an output that looks similar to cat N PL. Here are some more examples:
mouse |
| mouse N SG |
mice |
| mouse N PL |
foxes |
| fox N PL |
Morphological parsing yields information that is useful in many NLP applications. In parsing, e.g., it helps to know the agreement features of words. Similarly, grammar checkers need to know agreement information to detect such mistakes. But morphological information also helps spell checkers to decide whether something is a possible word or not, and in information retrieval it is used to search not only cats, if that's the user's input, but also for cat.
To get from the surface form of a word to its morphological analysis, we are going to proceed in two steps. First, we are going to split the words up into its possible components. So, we will make cat + s out of cats, using + to indicate morpheme boundaries. In this step, we will also take spelling rules into account, so that there are two possible ways of splitting up foxes, namely foxe + s and fox + s. The first one assumes that foxe is a stem and s the suffix, while the second one assumes that the stem is fox and that the e has been introduced due to the spelling rule that we saw above.
In the second step, we will use a lexicon of stems and affixes to look up the categories of the stems and the meaning of the affixes. So, cat + s will get mapped to cat NP PL, and fox + s to fox N PL. We will also find out now that foxe is not a legal stem. This tells us that splitting foxes into foxe + s was actually an incorrect way of splitting foxes, which should be discarded. But note that for the word houses splitting it into house + s is correct.
Here is a picture illustrating the two steps of our morphological parser with some examples.
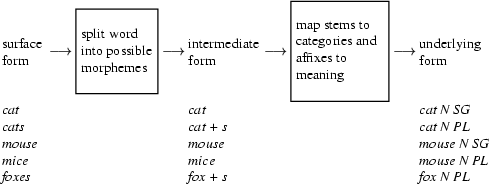
We will now build two transducers: one to do the mapping from the surface form to the intermediate form and the other one to do the mapping from the intermediate form to the underlying form.