10.3.4 From Syntax to Semantics
In order to approach Task 1, we will use a simple context free grammar like the ones we've seen in previous lectures.
Task 1 
In order to approach Task 1, we will use a simple context free grammar like the ones we've seen in previous lectures. As ususal, the syntactic analysis of a sentence will be represented as a tree whose non-leaf nodes represent complex syntactic categories (such as S, NP and VP) and whose leaves represent lexical items (these are associated with lexical categories such as noun, transitive verb, determiner, proper name and intransitive verb). To enhance the readability of such trees, we will ommit the non-branching steps and take for instance 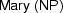 as a leave node.
as a leave node.
Let's have a second look at our semantically annotated syntax-tree for the sentence ``John loves Mary'' (from Section 10.3.2).
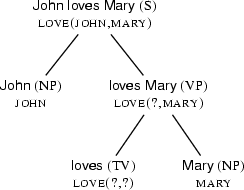
We said that the systematic contribution of syntactic structure to semantic construction consists in guiding the semantic contributions of words and phrases to the right places in the final semantic representation. Obviously, when we contructed the formula  along the above syntax tree, we made tacit use of a lot of knowledge about how exactly syntactic information should be used. Can we make this knowledge more explicit?
along the above syntax tree, we made tacit use of a lot of knowledge about how exactly syntactic information should be used. Can we make this knowledge more explicit?
Let's take a step back. What's the simplest way of taking over syntactic information into our semantic representation? Surely, the following is a very undemanding first step:
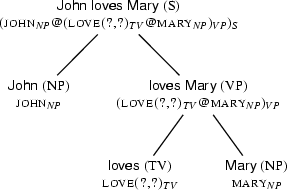
We've simply taken the semantic contributions of words and phrases, uniformly joined them with an @-symbol, and encoded the tree structure in the bracketing structure of the result. Yet the result is still quite far from what we actually want to have. It definitely isn't a first order formula. In fact we've only postponed the question of how to exploit the syntactic structure for guiding arguments to their places. What we've got is a nice linear ``proto''-semantic representation, in which we still have all syntactic information at hand. But this representation still needs a lot of post-processing.
What we could now try to do is start giving post-procesing rules for our ``proto''-semantic representation, rules like the following:``If you find a transitive verb representation between two @-symbols, always take the item to its left as first argument, and the item to its right as second argument.''
Formulating such rules would soon become very complicated, and surely our use of terms like ``item to the left'' indicates that we've not yet reached the right level of abstraction in our formulation. In the next section, we're going to look at 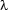 -calculus, a formalism that gives us full flexibility in speaking about missing pieces in formulas, where they're missing, and when and from where they should be supplied. It provides the right level of generality for capturing the systematics behind the influence that syntactic structure has on meaning construction. Post-processing rules like the one just seen won't be necessary, their role is taken over by the uniform and very simple operation of
-calculus, a formalism that gives us full flexibility in speaking about missing pieces in formulas, where they're missing, and when and from where they should be supplied. It provides the right level of generality for capturing the systematics behind the influence that syntactic structure has on meaning construction. Post-processing rules like the one just seen won't be necessary, their role is taken over by the uniform and very simple operation of 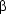 -reduction.
-reduction.