2.1.3 Separating out the Lexicon
Design of FSAs for linguistic applications.
In Exercise 1.1 you were asked to construct a finite state automaton recognizing those English noun phrases that can be built from the words the, a, wizard, witch, broomstick, hermione, harry, ron, with, fast. The FSA that you came up with probably looked similar to this:
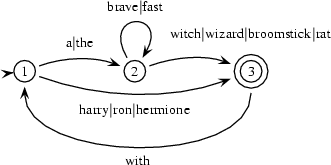
Let's call this automaton b1. So it is
start(b1,1).
final(b1,3).
trans(b1,1,2,a).
trans(b1,1,2,the).
trans(b1,2,2,brave).
trans(b1,2,2,fast).
trans(b1,2,3,witch).
trans(b1,2,3,wizard).
trans(b1,2,3,broomstick).
trans(b1,2,3,rat).
trans(b1,1,3,harry).
trans(b1,1,3,ron).
trans(b1,1,3,hermione).
trans(b1,3,1,with). in Prolog (this automaton and the next are specified in harry.pl ).
Now, what would Prolog answer if we used the parser of the previous section on this automaton? Let's parse the input [the,fast,wizard]:
testparse(b1,[the,fast,wizard],Parse). The call instantiates Parse=[1,the,2,fast,2,wizard,3]. This tells us how the FSA was traversed for recognizing that this input is indeed a noun phrase. But wouldn't it be even nicer if we got a more abstract explanation? E.g. one saying that [the,fast,wizard] is a noun phrase because it consists of a determiner, followed by an adjective, which is in turn followed by a common noun. That is, we would like the parser to return something like this:
[1,det,2,adj,2,noun,3].Actually, you were probably already making a similar abstraction when you were thinking about how to construct that FSA. You were probably thinking: ``Well, a noun phrase starts with a determiner, which can be followed by zero or more adjectives, and it must end in a noun; ``the'' and ``a'' are the determiners that I have, so I need a ``the'' and an ``a'' transition from state 1 to state 2.'' In fact, it would be a lot nicer if we could specify transitions in the FSA based on syntactic categories like determiner, common noun, and so on, and additionally give a separate lexicon specifying what words belong to each category. Like this, for example:
start(b2,1).
final(b2,3).
trans(b2,1,2,det).
trans(b2,2,2,adj).
trans(b2,2,3,cn).
trans(b2,1,3,pn).
trans(b2,3,1,prep).
lex(a,det).
lex(the,det).
lex(fast,adj).
lex(brave,adj).
lex(witch,cn).
lex(wizard,cn).
lex(broomstick,cn).
lex(rat,cn).
lex(harry,pn).
lex(hermione,pn).
lex(ron,pn).
It's not very difficult to change our recognizer to work with FSA specifications that, like the above, define their transitions in terms of categories instead of symbols and then use a lexicon to map those categories to symbols or the other way round. The only thing that changes is the definition of the traverse predicate. We don't simply compare the label of the transition with the next symbol of the input anymore, but have to access the lexicon to check whether the next symbol of the input is a word of the category specified by the label of the transition. That means, instead of
traverse('#',String,String).
traverse(Label,[Label|Symbols],Symbols).we use
traverse('#',String,String).
traverse(Label,[Symbol|Symbols],Symbols) :-
lex(Symbol,Label).
A recognizer for FSAs with categories (using the above version of traverse/3 can be found in cat_parse.pl .