6.5.1 The General Idea
Top-down parsing/recognition.
Remember that in bottom-up parsing/recognition we start at the most concrete level (the level of words) and try to show that the input string has the abstract structure we are interested in (this usually means showing that it is a sentence). So we use our CFG rules right-to-left.
In top-down parsing/recognition we do the reverse: We start at the most abstract level (the level of sentences) and work down to the most concrete level (the level of words). So, given an input string, we start out by assuming that it is a sentence, and then try to prove that it really is one by using the rules left-to-right. That works as follows: If we want to prove that the input is of category 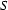 and we have the rule
and we have the rule 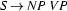 , then we will try next to prove that the input string consists of a noun phrase followed by a verb phrase. If we furthermore have the rule
, then we will try next to prove that the input string consists of a noun phrase followed by a verb phrase. If we furthermore have the rule 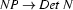 , we try to prove that the input string consists of a determiner followed by a noun and a verb phrase. That is, we use the rules in a left-to-right fashion to expand the categories that we want to recognize until we have reached categories that match the preterminal symbols corresponding to the words of the input sentence.
, we try to prove that the input string consists of a determiner followed by a noun and a verb phrase. That is, we use the rules in a left-to-right fashion to expand the categories that we want to recognize until we have reached categories that match the preterminal symbols corresponding to the words of the input sentence.
Of course there are lots of choices still to be made. Do we scan the input string from right-to-left, from left-to-right, or zig-zagging out from the middle? In what order should we scan the rules? More interestingly, do we use depth-first or breadth-first search?
In what follows we'll assume that we scan the input left-to-right (that is, the way we read) and the rules from top to bottom (that is, the way Prolog reads). But we'll look at both depth first and breadth-first search.