IGK 2004 Project
| Proposers | : Chris Callison-Burch and Colin Bannard |
| Other interested students | : Beatrice Alex, Marco Kuhlmann |
| Suggested Lecturers/Guests | : Regina Barzilay Rebecca Hwa |
| Time constraints | : Chris will be away for the second week |
Previous work on extracting paraphrases has focused on the use of monolingual parallel corpora (Barzilay 2003,Barzilay 2001,Ibrahim 2003). Since monolingual parallel corpora are relatively rare -- sources for this kind of corpus come in the form of multiple translations of foreign language novels, and multi-reference translations produced for machine translation evaluations that use automatic scoring metrics like Bleu (Papineni 2001). By contrast, bilingual parallel corpora are very common. We hope that because they are so common that we can produce paraphrases for a wider variety of language usage, and possibly produce paraphrases of a higher quality.
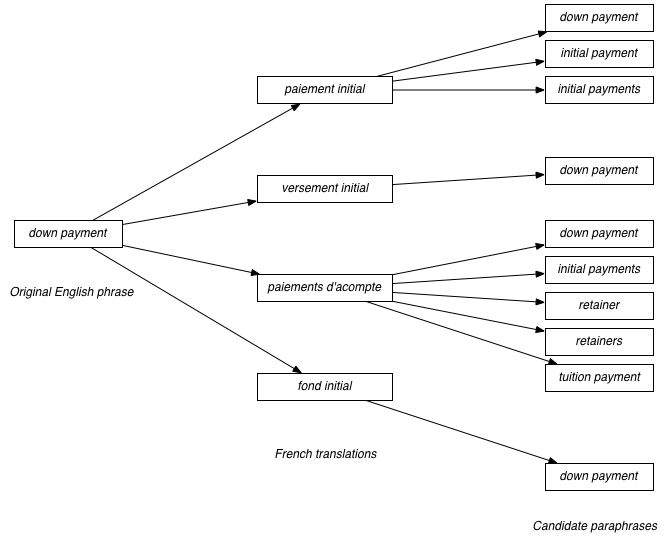
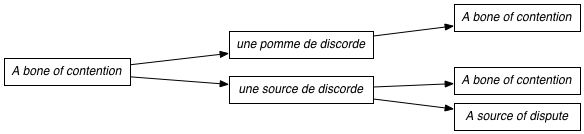
Our proposed method for extracting paraphrases is to use a phrase-based translation model. The idea is to take an English phrase, look up its translations into another language, and then look up all the English phrases that those foreign language phrases translate to. Two examples of this are shown below:
We have formulated a method for calculating the paraphrase probability given a set of candidate probabilities. The way that we will calculate this probability is using translation probabilities, which generally look at the counts of how often a phrase aligns with another phrase in a parallel corpus:
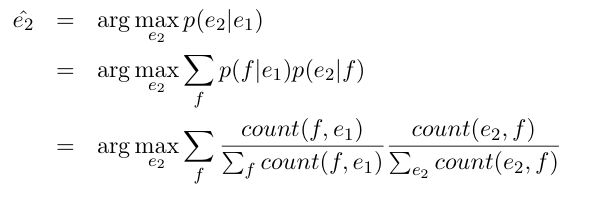
If we extracted a set of paraphrases as follows
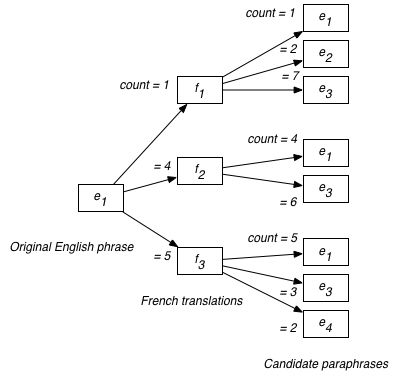
then we would calculate the probabilities as
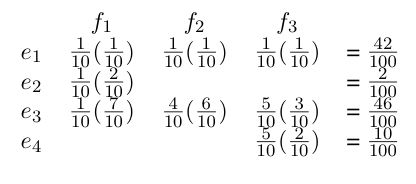
And thus e3 would be considered the best paraphrase.
The main goals of this project will be to
Regina Barzilay and Lillian Lee. Learning to paraphrase: An unspervised approach using multiple-sequence alignment. In Proceedings of HLT/NAACL 2003.
Regina Barzilay and Kathleen McKeown. Extracting paraphrases for a parallel corpus. In Proceedings of ACL 2001.
Ali Ibrahim, Boris Katz, and Jimmy Lin. Extracting structural paraphrases from aligned monolingual corpora. In Proceedings of the Second International Workshop on Paraphrasing (ACL 2003), 2003.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. IBM Research Report RC22176(W0109-022), IBM, 2001.