Event pictures
Photos of the event are now available. Follow this link to see pictures taken during the Scientific program, and follow this link to see pictures of the Evening program. All pictures were taken by Beatrice Fischer.
Schedule
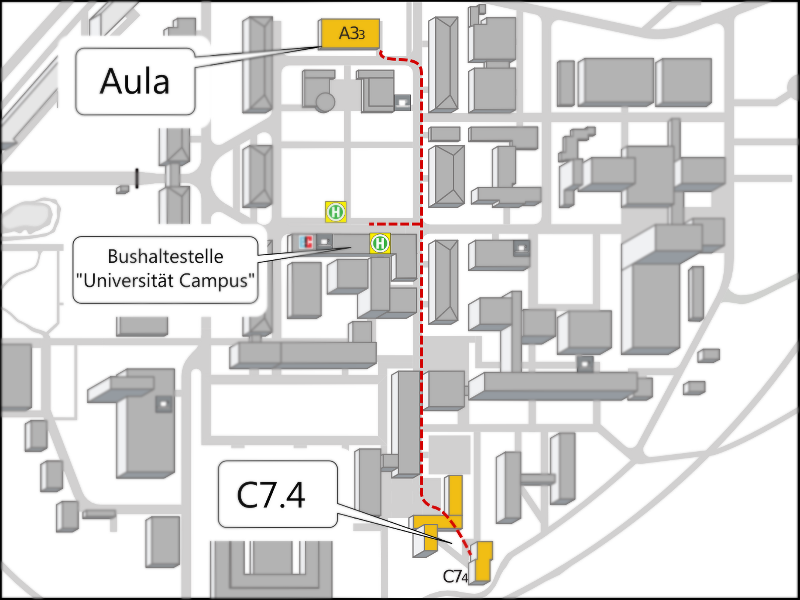
14:00 - Scientific program with posters and demos, Building C7.4
Coli researchers and students will present current research and research from the past 25 years. We also invited presentations of any kind from alumni – we asked them to share their research with us, tell us about their experiences in industry, or anything else. We are thrilled to see what they’ve been up to! Check the program below for more info.
17:00 - Champagne reception, Building C7.4
Warm up for the evening program with champagne and some words from Manfred Pinkal.
18:00 - Invited talks, Aula
Remember the past 25 years of Coli and Phonetics and look forward into our future with our guest speakers.
Brief speeches by guests from politics and university:
- Prof. Dr. Manfred Schmitt, President of Saarland University
- Dr. Susanne Reichrath, Staatskanzlei des Saarlandes
- Prof. Dr. Margret Wintermantel, Chairwoman of the University Council
- Prof. Dr. Wolfgang Wahlster, CEO and Scientific Director of the DFKI
Invited talks:
- Prof. Dr. Hans Uszkoreit, DFKI and (formerly) Saarland University:
Our field had been super cool long before it got hyper hot
- Prof. Dr. William Barry, (formerly) Saarland University:
Reflections of SB Phonetics in the Nineties and ‘Noughties
- Prof. Dr. Elke Teich, Saarland University:
The times they are a-changin’: From Coli to LST in 25 years
- Prof. Dr. John Nerbonne, Rijksuniversiteit Groningen and University of Freiburg:
The view from a distance
19:30 - Social program, Aula
Catch up with old and new Coli friends over dinner and drinks!
Location Map
Detailed scientific program
Exhibition on Writing Systems
Jürgen Trouvain (UdS), Christophe Biwer (UdS), Sascha Keßler (UdS), Christine Schäfer (UdS), Anna Welker (UdS), Maximilian Wolf (UdS)
This exhibition, emerged from a seminar in summer semester 2016 and organized by Coli students and their lecturer, covers various aspects of writing systems. One part is on the diversity of non-Roman writing systems with a different representations of vowels, consonants, syllables, and morphemes (Greek, Cyrillic, Georgian, Hebrew, Arabic, Korean, Sanskrit-based scripts, Chinese, Japanese). Another part is on the notation of phonetic events including segments, speech melody and also music, but also gestures in a sign language. The construction and reconstruction of alphabets and coding schemes play a key role for artificial and other unscripted languages, the decipherment of secret messages and unknown scripts, Morse code, writing in shorthand, and Braille. The exhibition closes with aspects of hand-writing, machine-writing, and ‘language technology’ in the 15th century.
Exploring the driving simulator lab
Katja Häuser (UdS), Janek Amann (UdS), & Valentin Kany (UdS)
We present a demo of our driving simulator. By means of the driving simulator we investigate age-related differences in driving safety and how in-vehicle communication modulates cognitive load in drivers.
Visit to the phonetics recording lab
Members of the phonetics group
The lab provides facilities and equipment for professional-quality speech recordings and for speech production and perception studies, in research and teaching. The sound-insulated recording booth is suitable for single-speaker and dialog recordings.
Kempelen’s speaking machine as the beginning of mechanical speech synthesis
Fabian Brackhane (IDS Mannheim) & Jürgen Trouvain (UdS)
Wolfgang von Kempelen (1734-1804) is famous for his “Mechanical Turk”, a chess-playing automaton operated by a human hidden in the machine. The “Amazon Mechanical Turk” has been named after the “Chess Turk” by using human intelligence to perform tasks that computers are currently unable to do. His other great invention was his speaking machine which marks the beginning of mechanical speech synthesis. The Saarbrücken replica of this engineering masterpiece is based on his descriptions he gave in the book “Wolfgangs von Kempelen k.k. wirklichen Hofraths Mechanismus der menschlichen Sprache nebst der Beschreibung seiner sprechenden Maschine”, published in 1791. In 2017, we published together with Richard Sproat (Google New York) a new edition of the “mechanism” in a transliterated and commented version which was also translated into English for the first time. Kempelen’s book represents a milestone for experimental phonetics and early speech technology.
Impact of prosodic structure and information density on vowel space size
Erika Brandt (UdS)
We investigated the influence of prosodic structure and information density on vowel space size. Vowels were measured in five languages from the BonnTempo corpus, French, German, Finnish, Czech, and Polish, each with three female and three male speakers. Speakers read the text at normal, slow, and fast speech rate. The Euclidean distance between vowel space mid-point and formant values for each speaker was used as a measure for vowel distinctiveness. The prosodic model consisted of prominence and boundary. Information density was calculated for each language using the surprisal of the biphone X n | X n-1. On average, there is a positive relationship between vowel space expansion and information density. Detailed analysis revealed that this relationship did not hold for Finnish, and was only weak for Polish. LMM analysis showed that prominence, decelerated speech rate, and surprisal showed significant positive results. Also, surprisal interacted positively with stress and vowel identity.
Shadowing Synthesized Speech – Segmental Analysis of Phonetic Convergence
Iona Gessinger (UdS), Eran Raveh (UdS), Sébastien Le Maguer (UdS), Bernd Möbius (UdS), & Ingmar Steiner (UdS)
To shed light on the question whether humans converge phonetically to synthesized speech, a shadowing experiment was conducted using three different types of stimuli – natural speaker, diphone synthesis, and HMM synthesis. Three segment-level phonetic features of German that are well-known to vary across native speakers were examined. The first feature triggered convergence in roughly one third of the cases for all stimulus types. The second feature showed generally a small amount of convergence, which may be due to the nature of the feature itself. Still the effect was strongest for the natural stimuli, followed by the HMM stimuli and weakest for the diphone stimuli. The effect of the third feature was clearly observable for the natural stimuli and less pronounced in the synthetic stimuli. This is presumably a result of the partly insufficient perceptibility of this target feature in the synthetic stimuli and demonstrates the necessity of gaining fine-grained control over the synthesis output, should it be intended to implement capabilities of phonetic convergence on the segmental level in spoken dialogue systems.
Fast & Easy: Approximating Uniform Information Density in Language Production
Jesús Calvillo (UdS)
A model of sentence production is presented, which implements a strategy that produces sentences with more uniform surprisal profiles, as compared to other strategies, and in accordance to the Uniform Information Density Hypothesis (Jaeger, 2006; Levy & Jaeger, 2007). The model operates at the algorithmic level combining information concerning word probabilities and sentence lengths, representing a first attempt to model UID as resulting from underlying factors during language production. The sentences produced by this model showed indeed the expected tendency, having more uniform surprisal profiles and lower average word surprisal, in comparison to other production strategies.
Fine-grained POS Tagging of German Social Media and Web Texts
Stefan Thater (UdS)
This paper presents work on part-of-speech tagging of German social media and web texts. We take a simple Hidden Markov Model based tagger as a starting point, and extend it with a distributional approach to estimating lexical (emission) probabilities of out-of-vocabulary words, which occur frequently in social media and web texts and are a major reason for the low performance of off-the-shelve taggers on these types of text. We evaluate our approach on the recent EmpiriST 2015 shared task dataset and show that our approach improves accuracy on out-of-vacabulary tokens by up to 5.8%; overall, we improve state-of-the-art by 0.4% to 90.9% accuracy.
ERP time-course of (pseudo-)word form activation and integration
Yoana Vergilova (UdS)
We investigated the effect of high- and low-predictability sentence contexts on the comprehension of words and similar-looking pseudo-words. We aimed to establish whether top-down context support affords for facilitation for bottom-up activation of both words and pseudo-words. Based on previous ERP findings, we explored both early (N170) and later (N400 and P600) components. Our data indicated that pseudo-word forms are distinguished from word forms early on (N170), regardless of context support. At N400 time-windows high-predictability contexts facilitated pseudo-word comprehension similarly to words comprehension, but to a lesser extent. Later positivities indicated topographic differences at word and pseudo-word repair/integration and re-analysis.
The influence of script knowledge on expectations: Evidence from ERPs
Francesca Delogu (UdS), Heiner Drenhaus (UdS), & Matthew Crocker (UdS)
While reading about everyday activities, comprehenders use script knowledge to build a representation of the situation described. Previous work has demonstrated that such knowledge guides processing of incoming input by making event boundaries more or less expected. We present an ERP study investigating whether expectations for event boundaries are influenced by how elaborately everyday activities are represented. Participants read short stories describing a common event in either brief or elaborate manner. The final sentence contained a target word referring to a more predictable fine event boundary or to a less predictable coarse event boundary. The results revealed an N400 effect of event boundary and a frontal positivity for elaborate compared to brief descriptions, which was larger for less predictable targets. We interpret the two effects as indexing two stages of situation model construction: Retrieval of lexical-semantic information (N400) and updating of the situation model (P600).
Informationally redundant event descriptions alter prior beliefs about the common ground
Ekaterina Kravtchenko (UdS)
Theories of pragmatics and language processing predict that speakers avoid excessive redundancy. Informationally redundant utterances (IRUs) are, however, common in discourse. It’s unclear how comprehenders interpret these utterances, and whether they make attempts to reconcile ‘dips’ in informational utility with expectations of informativity. We show that IRUs trigger pragmatic inferences, which increase utterance utility in line with listener expectations. In 3 studies, we look at utterances which refer to stereotyped event sequences (scripts), such as ‘John went grocery shopping. He paid the cashier!’. When comprehenders encounter such utterances, they reason that the event description must convey new, unstated information (e.g., that ‘John’ is a habitual non-payer). We further show that the degree to which such inferences are triggered is dependent on prosodic or discourse framing. The results demonstrate that conceptual redundancy leads to listeners revising the common ground, to accommodate dips in informational utility, provided that context supports the inference.
Linguistic Measures of Pitch Range in Slavic and Germanic Languages.
Bistra Andreeva (UdS), Bernd Möbius (UdS), Grazyna Demenko (Adam Mickiewicz University), Frank Zimmerer (UdS), Jeanin Jügler (IDS Mannheim)
Based on specific linguistic landmarks in the speech signal, this study investigates pitch level and pitch span differences in English, German, Bulgarian and Polish. Pitch level appeared to have significantly higher values for the female speakers in the Slavic than the Germanic group. The male speakers showed slightly different results, with only the Polish speakers displaying significantly higher mean values for pitch level than the German males. Overall, the results show that the Slavic speakers tend to have a wider pitch span than the German speakers. But for the linguistic measure we only find the difference between Polish and German speakers. We found a flatter intonation contour in German than in Polish, Bulgarian and English speakers and differences in the frequency of the landmarks between languages. Concerning “speaker liveliness” we found that the speakers from the Slavic group are significantly livelier than the speakers from the Germanic group.
Textkernel - Machine Learning for Matching People and Jobs
Beata Nyari (Textkernel)
At Textkernel we develop intelligent software for understanding unstructured data – resumes and job ads, in order to connect supply to demand on the job market. The solutions involve various fields including NLP, machine learning, information extraction and retrieval, web mining and recommendation systems. R&D at Textkernel consists of three main directions: multilingual resume and job parsing, semantic searching and matching, and ontology building. I will be discussing several exciting projects in which our team is currently involved. I will show how deep learning is helping us to achieve high parsing accuracy and create document parsing models for new languages much faster than it would be possible with traditional machine learning models. I will also present how we built a deep neural network classifier with little data to perform entity linking: mapping job titles into a job ontology of more than 5000 professions.
In Bildern Sprechen (iBiS) - Vergleichendes Metaphernlexikon Japanisch-Deutsch
Annely Rothkegel (University Politehnica Bucuresti; WaK) & Ryuko Kobayashi-Woirgardt (Japanisch-Unterricht für Gymnasiasten)
iBiS ist ein Ausstellungsprojekt (web exhibition project) über die sprachliche Kreativität, die bei den metaphorischen Redewendungen in der Analogie von Bild- und Denkwelten eine besondere Anschaulichkeit erreicht. Metaphern gehören zum produktiven Bestandteil der Begriffsbildung in Wissenschaft, Politik, Wirtschaft, Technik sowie Alltag und vermitteln als lexikalisiertes Inventar einer Sprache kognitive und sinnliche Zugänge zum Kennenlernen von Sprachen und Kulturen. Zum Ansatz: Das geplante Portal zum Sprachvergleich Japanisch-Deutsch präsentiert die Systematik von Bildwelten aus dem Kosmos der “Vier Elemente” (Wasser, Feuer, Erde, Luft) und zeigt sie als “Sprechen in Bildern”, die für abstrakte Konzepte menschlichen Seins und Handelns stehen. Ausgewählt werden solche Ausdrücke, die in Bild und Konzept weltweit verbreitet sind (“widespread idioms”, Fisch im Wasser) wie auch solche , die nur im jeweiligen kulturellen Kontext zu verstehen sind (jap 水清ければ月宿る [nur klares Wasser beherbergt den Mond]). Die lexikographische Organisation berücksichtigt Zugriffe aus jeder Sprache über einen Index, Äquivalenzmuster sowie Bild- und Konzeptfelder.
Efficient techniques for parsing with tree automata
Jonas Groschwitz (UdS)
Parsing for a wide variety of grammar formalisms can be performed by intersecting finite tree automata. This leads to very general algorithms that are widely applicable, but naive implementations can be quite inefficient. We present techniques that drastically speed up tree automata-based parsing, by either integrating formalism-specific indexing structures deep into the algorithm, or condensing similar rules into one. This makes parsing with tree automata practically feasible on realistic data when applied to context-free, TAG, and graph parsing, with the runtimes for graph parsing actually being the best in the literature.
Integrated sentence generation with charts
Nikos Engonopoulos (UdS)
Integrating surface realization and the generation of referring expressions (REs) into a single algorithm can improve the quality of the generated sentences. Existing algorithms for doing this, such as SPUD and CRISP, are search-based and can be slow or incomplete. We offer a chart-based algorithm for integrated sentence generation which supports efficient search through chart pruning.
Information Density and the Predictability of Phonetic Structure
Bernd Möbius (UdS), Bistra Andreeva (UdS), Frank Zimmerer (UdS), Erika Brandt (UdS), Zofia Malisz (KTH Royal Institute of Technology), Yoonmi Oh (Université de Lyon; CNRS)
SFB 1102 addresses the relation between information density and linguistic encoding in phonetics and human speech processing. The effects of information density on speakers’ choices in production and listeners’ preferences in perception are investigated in selected phonetic and phonological domains, in particular at the syllable and word levels and in local and non-local collocations. The project will analyse how the phonetic encoding density is modulated by systematic changes in the phonetic structure and its acoustic-phonetic features as a function of the predictability and the surprisal level of the linguistic expression. Experimental methods include the analysis of production data, phonetic perception tests, and comprehension tasks.
The diachronic development of combining forms in English corpora of scientific writing
Katrin Menzel (UdS) & Stefania Degaetano-Ortlieb (UdS)
This poster addresses the diachronic development of combining forms in English scientific texts over approximately 350 years, from the early stages of the first scholarly journals that were published in English to contemporary English scientific publications. The category of combining forms is presented and a case study examines the role of selected combining forms in two diachronic English corpora.
Congruency effects of speaker’s gaze on listeners’ sentence comprehension
Torsten Kai Jachmann (UdS)
Eye-tracking studies demonstrate the influence of speaker gaze in visually-situated spoken language. We present an ERP experiment examining the influence of speaker’s gaze congruency on listener’s comprehension of referential expressions related to a shared visual scene. We demonstrate that gaze toward objects elicits expectations to the upcoming words. Compared to a congruent gaze condition, we observe an increased N2 followed by an increased N400 when (a) the lack of gaze allows for multiple predictions of the upcoming noun, and (b) when the noun violates gaze-driven expectations.
The interplay of specificity and referential entropy reduction in situated communication
Elli Tourtouri (UdS)
In situated communication, reference can be established with expressions conveying either precise (Minimally-Specified, MS) or redundant (Over-Specified, OS) information. There is no consensus, however, concerning whether OS hinders referential processing or not (e.g., Arts et al. 2011; Engelhardt et al. 2011). I will present ERP evidence that OS facilitates processing. Further, I will examine an information theoretic explanation of this facilitation. That is, as incoming words restrict the referential domain, they incrementally contribute to the reduction of uncertainty about the target (referential entropy). I will present eye-tracking data suggesting that processing is facilitated, when entropy is reduced uniformly across the utterance, and particularly when the expression is over-specified. Finally, I will present a production study that seeks to provide further support to this explanation, testing whether speakers try to optimise for the reduction of referential entropy in situated communication, and whether the use of redundant adjectives is a strategy to do so.
Generating Data Comics
Kristina Striegnitz (Union College)
Large amounts of data are available today on almost any topic. Experts analyze this data, using sophisticated statistics and visualization tools, to discover trends and relationships, and increasingly, decisions that have far reaching effects on many people are made based on their findings. It is, therefore, important to communicate the results of data analytics in a way that is accessible to a non-expert audience. We propose that data analytics can be made accessible to a broader audience by presenting the results as a data story told through a sequence of visualizations accompanied by explanatory text (similar to a comic strip). The poster will present an overview of a system that automatically generates such data comics from multi-dimensional datasets. (Joint work with Klaus Mueller, Stony Brook University. Supported by the NSF, grant no. 1527112.)
Structuring information in interactive natural language generation
Martín Villalba (UdS)
We present a statistical model for predicting how the user of an interactive, situated NLP system resolved a referring expression. The model makes an initial prediction based on the meaning of the utterance, and revises it continuously based on the user’s behavior. The combined model outperforms its components in predicting reference resolution and when to give feedback.
Sentiment Analysis for German in Teaching, Research, and Society
Melanie Siegel (Hochschule Darmstadt)
One of the topics I have been dealing with in recent years is sentiment analysis for the German language. As a professor at a university of applied sciences, I combine the treatment of this topic in teaching and research. I also examine the societal aspects of the topic and take part in the public debate. In my teaching I work with students on projects that investigate different aspects of the topic. Research is concerned with cooperation with research groups in the IGGSA Interest Group on German Sentiment Analysis. The public debate is about the automatic recognition of fake opinions and about hate speech detection.
Mining Company Risk Registers from the Reuters News Archive
Jochen L. Leidner (Thomson Reuters)
We present the results of applying a supervised classifier to the practical problem of extracting a list of risks that a company or set of companies are exposed to. We apply the model to a year’s worth of the Reuters News Archive (RNA). The results can be utilized by downstream applications as <COMPANY; IS-EXPOSED-TO; RISKTYPE> RDF triples, delivered by a REST API. In our demonstration, we present the results in an interactive D3 visualization, which provides a step from manual to computer-supported risk identification.
PAD-E – An Affective Behavior Model for Embodied Agents
Norbert Pfleger (SemVox GmbH)
Based on the Sanbot robot by Qihan Technology (China), SemVox showcases how external triggers (stimuli) create artificial emotions and mood changes in the robot, using the PAD-E emotional state model. The PAD-E is a mathematical model that is used to display emotions and emotional state changes in a three-dimensional space. The dimensions are pleasure, arousal and dominance. The values within this space can be used to map discrete emotions such as joy, anger or gratitude. The emotions are injected into the space by the appraisal, which is everything that affects the emotional state in a situation. Intensity and duration of stimuli effects can be varied.
Machine Translation Services in EU Institutions
Andreas Eisele et al. (European Commission (DGT), Luxembourg)
We will explain and demonstrate the Machine Translation service of the European Commission, which was developed by the Directorate-General for Translation (DGT) under the name MT@EC since 2010, and which is currently being generalised and extended as a building block within the Connecting Europe Facility (CEF) under the label eTranslation.
The translation engines are trained using the vast Euramis translation memories, comprising over 1 billion sentences in the 24 official EU languages, produced by the translators of the EU institutions over the past decades.
The basic technologies behind these MT services were developed within EU projects coordinated by CoLi (Euromatrix) and DFKI (Euromatrix+) and many follow-up activities, which shows the high relevance of research in computational linguistics for large-scale real-word applications, serving public administrations, citizens and businesses in the EU.
Metalogue Virtual Negotiation Coach
Volha Petukhova (UdS) & Andrei Malchanau (UdS)
METALOGUE Multimodal Negotiation Agent is an adaptive dialogue system and has been designed within EU funded METALOGUE project (www.metalogue.eu). It presents a multimodal conversational system with the integrated cognitive agent technology. The virtual agent - META – communicates with users in natural language (English) within a negotiation based scenario. META is not only a conversational partner that exhibits plausible negotiation behavior, but is also a coach who trains efficient negotiation skills to achieve win-win outcomes.
On the need of Cross Validation for Discourse Relation Classification
Wei Shi (UdS)
The task of implicit discourse relation classification has received increased attention in recent years, including two CoNNL shared tasks on the topic. Existing machine learning models for the task train on sections 2-21 of the PDTB and test on section 23, which includes a total of 761 implicit discourse relations. This poster presents a methodological point, arguing that the standard test set is too small to draw conclusions about whether the inclusion of certain features constitute a genuine improvement, or whether one got lucky with some properties of the test set, and argue for the adoption of cross validation for the discourse relation classification task by the community.
Crosslingual Annotation and Analysis of Implicit Discourse Connectives for Machine Translation
Frances Yung (UdS)
Usage of discourse connectives (DCs) differs across languages, thus addition and omission of connectives are common in translation.
We investigate how implicit (omitted) DCs in the source text impacts various machine translation (MT) systems, and whether a discourse parser is needed as a preprocessor to explicitate implicit DCs.
Based on the manual annotation and alignment of 7266 pairs of discourse relations in a Chinese-English translation corpus, we evaluate whether a preprocessing step that inserts explicit DCs at positions of implicit relations can improve MT.
Results show that, without modifying the translation model, explicitating implicit relations in the input source text has limited effect on MT evaluation scores. In addition, translation spotting analysis shows that it is crucial to identify DCs that should be explicitly translated in order to improve implicit-to-explicit DC translation.
On the other hand, further analysis reveals that the disambiguation as well as explicitation of implicit relations are subject to a certain level of optionality, suggesting the limitation to learn and evaluate this linguistic phenomenon using standard parallel corpora.
Alto - Rapid Prototyping for Parsing and Translation
Christoph Teichmann (UdS)
We present Alto, a rapid prototyping tool for new grammar formalisms. Alto implements generic but efficient algorithms for parsing, translation, and training for a range of monolingual and synchronous grammar formalisms. It can easily be extended to new formalisms, which makes all of these algorithms immediately available for the new formalism.
LingoTurk: managing crowdsourced tasks for psycholinguistics.
Florian Pusse (UdS)
LingoTurk is an open-source, freely available crowdsourcing client/server system aimed primarily at psycholinguistic experimentation where custom and specialized user interfaces are required but not supported by popular crowdsourcing task management platforms. LingoTurk enables user-friendly local hosting of experiments as well as condition management and participant exclusion. It is compatible with Amazon Mechanical Turk and Prolific Academic. New experiments can easily be set up via the Play Framework and the LingoTurk API, while multiple experiments can be managed from a single system.
Talking Robots
Ivana Kruijff-Korbayova (DFKI)
The Talking Robots group that I lead in the MLT Lab at DFKI pursues research on various topics of dialogue processing in the context of human-robot interaction. In the TRADR project we investigate how to improve human-robot teaming for robot-assisted disaster response by supporting human-human and human-robot communication within a team. To this end we develop methods for processing situated multimodal dialogue about the goals and tasks of a mission and mission progress in dynamic unstructured environments. On the other hand, the PAL project focuses on human-robot interaction to strengthen self-management in children with Type 1 diabetes. We develop dialogue processing methods for long-term social interaction, consisting of various edutainment activities as well as social chats about topics related to a healthy lifestyle. My poster provides an overview of these research threads.
The European Master on Language and Communication Technologies (LCT)
Ivana Kruijff-Korbayova (DFKI)
The LCT program is an international distributed master course offered by a consortium of 7 universities in different european countries, coordinated by the Saarland University. It is designed to meet the demands of industry and research in the rapidly growing field of language technology. It provides students not only with profound knowledge and insight into computational linguistics a.k.a. natural language processing, but also with a unique international experience, because each student studies at two different partner universities, one year each. The course consists of compulsory core modules and elective advanced modules in Language Technology and Computer Science, possibly complemented by an internship project, and completed by a Master Thesis. Having fulfilled all study requirements, the students obtain two Master of Science/Arts degrees: one from each university where they studied. Do you have students or employees who would benefit from studying in the LCT program? Or do you work at a company who could offer internship/job placements to LCT students? Become part of our network. More details: www.lct-master.org
AcListant - Real-Time, Context-Aware Speech Recognition for Air Traffic Control
Marc Schulder (UdS) & Youssef Oualil (UdS)
Every day, air traffic controllers ensure the safety of airport airspace, instructing pilots during departure and landing. Human lives depend on their decisions, and psychological stress levels are high. To support the controller, digital assistance systems monitor the air traffic to suggest commands that will ensure timely and safe processing. However, the assistant can only see, but not hear. When the controller deviates from the assistant’s plan, it can take over 30 seconds for the change to become apparent on radar. Precious time in which the the controller can not rely on the assistant. To remedy this, researchers from the UdS Spoken Language Systems group (LSV), together with the German Aerospace Centre (DLR), developed AcListant, a new assistant system that uses robust context-sensitive speech recognition to allow the assistant to listen to the controller and adjust plans instantly. See the system in action at our demo! Adaptation for speech recognition systems is typically managed through acoustic or language model adaptation, but the primary techniques for doing this are either domain-specific or static and offline. Therefore we propose a real-time system which dynamically integrates situational context either pre- or post-recognition. Our co-located poster presents experimental results on 3 hours of real ATC data.
Data Science @ BAUR Versand
Caren Brinckmann (BAUR Versand)
baur.de zählt zu den 20 größten Online-Shops Deutschlands. Zu unseren Datenschätzen gehören Kunden- und Produktstammdaten, Clickstream-Daten, Daten aus den Callcentern, der Logistik, von Google u.v.m. Welchen Kundinnen sollen wir den neuesten Schuhkatalog schicken? Wen sollten wir per E-Mail an seinen noch nicht bestellten Warenkorb erinnern? Welche Produkte sollen wir der Shop-Besucherin zeigen, die ein “elegantes Kleid” sucht? Wie viel Cent sollten wir Google maximal bieten, damit unsere Anzeige zur Suchanfrage “gestreifter Badeanzug” möglichst weit oben angezeigt wird? All diese Fragen lassen sich nur dann effizient und treffsicher beantworten, wenn wir auf unseren Datenschätzen automatisiert statistische Prognosemodelle trainieren und dabei Methoden aus dem maschinellen Lernen, der Mustererkennung oder Deep Learning anwenden. Da es viele spannende Aufgaben gibt, freuen wir uns über Praktikanten und neue Kollegen, die sich für Statistik und Predictive Analytics begeistern und versiert mit SQL und einer Programmiersprache wie z.B. Python umgehen. Wer darüber hinaus noch Erfahrung mit Spark hat, ist uns besonders willkommen!
Acrolinx
Robert Grabowski (Acrolinx GmbH Berlin)
Acrolinx technology helps companies like IBM, Siemens, Google, Facebook, and Boeing to create content that’s on-brand, on-target, and at enterprise scale. The core of our product is a linguistic engine that analyzes written text, and guides authors to write with the right level of clarity and appropriate tone of voice. The software also checks for consistent use of terminology, suggests keywords for improved findability, and fixes spelling and grammar issues. Acrolinx provides guidance for English, German, Swedish, Japanese, and Chinese, with French and Spanish up next. We always strive to improve the guidance and are currently investigating how to combine rule-based approaches with machine learning techniques. The company, headquartered in the heart of Berlin, is a spin-off of the DFKI.
Text mining in pharma and healthcare using a data-driven approach
David Milward (Linguamatics)
This talk will provide background on Linguamatics and its growth to a 100 person company. It will look at applications in life sciences extracting knowledge from the scientific literature, and applications in healthcare such as risk assessment using electronic medical records. We will look at how NLP is playing an important role in supplying features for Machine Learning, and how a data-driven, semi-supervised approach avoids the bottleneck of requiring annotated training data.
Language science and technology at the University of Gothenburg
Asad Sayeed (University of Gothenburg)
In mid-2017, I moved from a postdoctoral research position at COLI@Uni-Saarland for a faculty position at the University of Gothenburg, Sweden. In this poster, I describe my transition to and current research in the recently-founded computational linguistics research group CLASP (Centre for Linguistic theory And Studies in Probability) at Gothenburg, which has a focus on dialogue systems and situated/embodied language understanding. Starting from key themes brought with me from my recent work at COLI, especially in event knowledge and quantifier scope processing, I describe my initial steps to build a research programme at Gothenburg and suggest opportunities my transition presents to build bridges between the closely overlapping research foci at Saarland and Gothenburg.
Psycholinguistic Models of Sentence Processing Improve Sentence Readability Ranking
David M. Howcroft (UdS)
While previous research on readability has typically focused on document-level measures, recent work in areas such as natural language generation has pointed out the need of sentence-level readability measures. Much of psycholinguistics has focused for many years on processing measures that provide difficulty estimates on a word-by-word basis. However, these psycholinguistic measures have not yet been tested on sentence readability ranking tasks. In this paper, we use four psycholinguistic measures: idea density, surprisal, integration cost, and embedding depth to test whether these features are predictive of readability levels. We find that psycholinguistic features significantly improve performance by up to 3 percentage points over a standard document-level readability metric baseline.
Morphological neighbors beat word2vec on the long tail
Clayton Greenberg (UdS)
Word embeddings use large amounts of training data to capture regularities that make their inclusion in NLP systems worthwhile. However, since the distribution of words is Zipfian, increasing the amount of data does not directly lower the proportion of rare words in the vocabulary. 21% of Vietnamese, 43% of German, 47% of Tagalog, and 55% of Turkish Polyglot (Al-Rfou et al., 2013) vocabularies are composed of words that occurred once or not at all in training data. Finding useful representations for these hapax legomena is a big problem, but other words also may not be well-served by standard embedding approaches. In this work, we ask and answer two questions: 1) What is the frequency distribution for words in common word similarity tasks? and 2) When does the morphologically-aware tool SwordSS (Singh et al., 2016) produce better embeddings than word2vec (Mikolov et al., 2013)?
Semantic Role Labeling
Michael Roth (UdS)
This poster discusses semantic role labeling, the task of mapping text to shallow semantic representations of eventualities and their participants. I will introduce the SRL task and discuss recent research related to the task. Poster attendees will learn about the linguistic motivation for semantic roles, and also about a range of computational models for this task, from early approaches to the current state-of-the-art.
Multitask Learning for Event Participant Embeddings
Xudong Hong (UdS)
We introduce a neural network model capturing both lexical and semantic features of event participants. Several possible methods to composite word and semantic role representations are explored. Making use of tensor factorisation on role-specific word embedding (Tilk et al. 2016), we represent the order-3 tensor feature space using 3 matrices. Then we add non-linearity and construct the model as a neural network. The model is trained in multitask style to counter both semantic role-filler prediction and semantic role-label prediction tasks. Comparing to previous works, the model has improvement on both semantic role/role-filler modelling and human thematic fit judgement correlations task. Moreover, the trained model has high accuracy on semantic role prediction.
The Electrophysiology of Language Comprehension: A Neurocomputational Model
Harm Brouwer (UdS)
We present a neurocomputational model of the electrophysiology of language processing. Our model is effectively a recurrent neural network that constructs a situation model of the state-of-the-affairs described by a sentence on a word-by-word basis. Each word leads to a processing cycle centred around two core operations. First, the meaning of an incoming word is retrieved/activated, the ease of which is reflected in N400 amplitude. Next, this retrieved word meaning is integrated with the current situation model into an updated situation model, which provides a context for both the retrieval and integration of the next word. The effort involved in situation model updating is indexed by P600 amplitude. We demonstrate how the model accounts for signature patterns of N400 and P600 modulations observed for a range of processing phenomena, including semantic anomaly, semantic expectancy (on nouns and articles), syntactic violations, garden-paths, and crucially, the much debated ‘semantic P600’-phenomenon.